はじめに
こんにちは!
レバレジーズデータ戦略室、データアナリストの内田です。
今回は、性格診断の結果を活用して、社員間の「性格類似度」を数値化する分析手法の一例をご紹介します。
人の性格や相性といった、これまで感覚的に捉えられることが多かった要素について、データを用いて定量的に評価する試みについて、その手法と考え方を解説していきます。
分析の目的
今回の分析が目指すことの一つは、「組織全体の活性化」に貢献することです。
そのアプローチの一環として、社員同士の性格的な類似性をデータに基づいて定量的に把握しました。この類似性に関する情報が、組織活性化に向けた取り組みの参考として、社内で活用されることを想定しています。
本分析で使用する「性格類似度」は、個人間の相性をわかりやすく示すために、0から100点の間で算出することにしました。 得点が高いほど、性格の類似度が高いことを意味します。
分析手法
1. ユークリッド距離の算出
各個人について、性格診断テストの結果として得られた16個の性格因子に関する数値データ(因子スコア)を用いて、個人間の「ユークリッド距離」を算出しました。 ユークリッド距離とは、多次元空間における二点間の直線距離を表します。
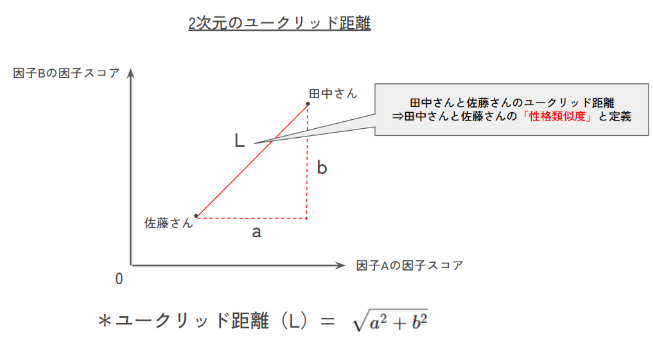
このユークリッド距離を、個人間の性格の類似度として定義しました。
ユークリッド距離の選定理由
今回の分析では、代表的な指標である「ユークリッド距離」と、各因子間の相関関係も考慮する「マハラノビス距離」の二つを候補として比較検討しました。
最終的にどちらの手法を採用するかを決める上で、一つ課題がありました。それは、「性格の類似度」には、例えば売上データのような明確な「正解」が存在しない、ということです。
そこで、私たちは実際に社内で互いをよく知る複数のメンバーに協力をお願いしました。そして、両方の距離指標から計算された「性格類似度スコア」を提示し、「どちらのスコアが、より普段感じている相性や関係性の実感に近いか」をヒアリングしました。
その結果、より多くのメンバーから「実感に近い」という評価を得られたのが「ユークリッド距離」でした。そのため、今回の分析ではユークリッド距離を採用することにしました。
このように、客観的な正解データがないテーマにおいては、最終的にその分析結果を利用する人々の感覚や定性的な評価を取り入れることも、実用的な指標を決定する上で有効なアプローチだと考えています。
2. ユークリッド距離をスケーリング
算出したユークリッド距離は、二人のメンバー間の性格的な「距離」を表します。つまり、値が小さいほど性格が似ていることを意味しますが、その数値だけを見ても、それが具体的にどの程度の「類似度」を示すのか、直感的に理解するのは難しいです。
そこで、このユークリッド距離を、より分かりやすい指標に変換する「スケーリング」という処理を行います。今回の分析では、冒頭で定義したように「0点から100点」で表され、「100点に近いほど類似度が高い」と解釈できるように数値データの尺度を変換することを行いました。
この変換を行うための具体的な手法として、今回は「ロジスティック関数」(シグモイド関数とも呼ばれます)を採用しました。
このロジスティック関数を用いたスケーリングにより、誰にとっても解釈しやすい形で社員間の相性を評価できるようにしました。
スケーリングに「ロジスティック関数」を採用した理由
算出したユークリッド距離を0点から100点のスコアに変換する方法として、まず一般的な「正規化」(データ全体の最小値を0点、最大値を100点に対応させる方法)を検討しました。
しかし、「正規化」を使う場合、将来新しい社員のデータが追加されるたびに、算出されるスコアが0点未満になったり、100点を超えてしまう可能性がありました。なぜなら、正規化は「その時点での」データ全体の最小値と最大値を基準にスコアを算出する手法だからです。そのため、新しいデータが追加されて最小値や最大値が更新されると、既存社員も含め全員のスコアを再計算する必要が生じ、結果としてスコアが0~100点の範囲を外れてしまう場合があります。
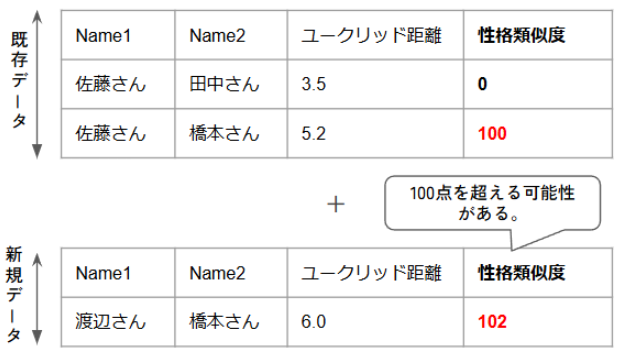
そこで、入力値(ユークリッド距離)が変化しても、出力されるスコアが常に安定して0点から100点の範囲に収まるように設計できる「ロジスティック関数」を採用しました。この方法なら、新しいデータが追加されても既存のスコアが変動することはなく、指標としての一貫性を保つことができます。
Pythonコード
※性格因子に関する数値データ(因子スコア)はダミーデータとしています。
import numpy as np import pandas as pd # 各人の因子スコア(16次元ベクトル) person1_scores = np.array([80, 50, 70, 60, 40, 90, 75, 65, 85, 55, 45, 80, 60, 70, 50, 90]) person2_scores = np.array([70, 60, 80, 50, 50, 80, 60, 70, 90, 60, 50, 70, 70, 60, 60, 80]) person3_scores = np.array([85, 45, 65, 70, 35, 95, 80, 60, 80, 50, 40, 85, 55, 75, 45, 95]) person4_scores = np.array([60, 70, 90, 40, 60, 70, 55, 75, 95, 65, 55, 60, 75, 55, 65, 75]) person5_scores = np.array([90, 40, 60, 80, 30, 100, 85, 55, 75, 45, 35, 90, 50, 80, 40, 100]) # 辞書でまとめて管理 persons = { "person2": person2_scores, "person3": person3_scores, "person4": person4_scores, "person5": person5_scores } # person1 とのユークリッド距離を計算 distances = [] for name, scores in persons.items(): distance = np.linalg.norm(person1_scores - scores) distances.append({"name": name, "euclid_distance": distance}) # DataFrame化 df = pd.DataFrame(distances) # ロジスティック(シグモイド)スケーリング関数 def scale_distance_sigmoid(df, distance_col="euclid_distance", a=1.0, output_col="scale_distance"): distance_x = df[distance_col].values std = np.std(distance_x) median = np.median(distance_x) distance_a = a / std distance_b = -distance_a * median distance_y = 1 / (1 + np.exp(distance_a * distance_x + distance_b)) df[output_col] = distance_y * 100 return df # スケーリング実行 df = scale_distance_sigmoid(df, a=1.0) # 結果表示 display(df)
3. 社内同士の性格類似度を可視化
算出された「性格類似度」は、特定の社員を基点として、他の全社員とのスコアを一覧で確認することができます。
例えば、自分自身と他の全社員との類似度スコアを確認したり、チームリーダーが自身のチームメンバーとの類似度スコアを確認したりすることが可能です。これにより、ある個人から見て、どの社員と性格的な類似度が高いのか、あるいは低いのかを、客観的な数値で簡単に把握できます。
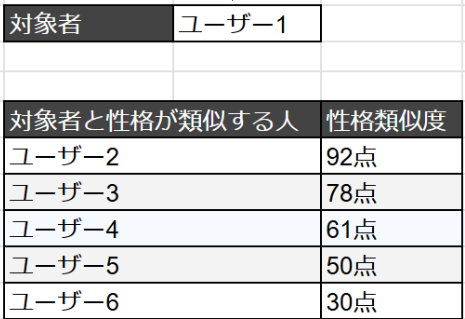
活用例
算出された「性格類似度」スコアは、例えば1on1ミーティングなどで、上司と部下がお互いを理解するための一つの参考情報として活用されることが期待できます。 またチーム編成を検討する際にも、このスコアが参考情報の一つとなるかもしれません。
まとめ
本記事では、性格診断の結果を用いて社員間の「性格類似度」を数値化する分析手法について、具体的な計算プロセスや指標選定の考え方を交えてご紹介しました。
このようなデータに基づいたアプローチが、少しでも皆様の参考になれば幸いです。
また、データ戦略室は、随時メンバーの募集をしておりますので、本記事でご紹介したような分析に興味を持たれた方はぜひ求人もご覧ください!