はじめに
こんにちは。
レバレジーズデータ戦略室、データアーキテクトの浅見です。
今回は、Tableau Cloudでの「データソース更新」に潜む落とし穴についてお話しします。
尚、本記事では「サーバー」から利用できるデータソース(レバレジーズでは「Google BigQuery」を接続)の更新をするケースに絞って言及していきます。
Tableauを使ってデータを可視化している方にとって、「データソースの更新」は避けて通れない重要なプロセスです。しかし、データソースの設計や更新方法次第では、更新が失敗しやすくなるリスクがあることをご存じでしょうか?
実際、レバレジーズのTableau環境でも、かつてはほぼ毎日、複数のデータソースで更新エラーが発生している状況がありました。
本記事では、その原因と対応策を振り返りながら、ダッシュボードを安定運用するための具体的なヒントをご紹介しています。
データソースの更新に悩んでいる方や、運用改善を検討している方の参考になれば幸いです。
データソース更新の種類
前提として、Tableauで「サーバー」から利用できるデータソースを更新する場合、①ライブ接続と②抽出接続の2パターンで更新が可能です。
それぞれの違いを以下に簡単に説明します。詳細はTableau公式のヘルプをご覧ください。
- ①ライブ接続
- データベースにリアルタイムで接続し、常に最新のデータを取得する方式
- ②抽出接続
- 指定したスケジュールや手動操作により、定期的にデータを取得する方式
レバレジーズでは、パフォーマンスと安定性を重視して「抽出接続」を採用しているケースが多く、Tableau Server上でスケジュールに基づいた定期的な抽出更新を行っています。
以降では、この「抽出更新」の運用において実際に発生した失敗事例と、それに対する対応策を紹介していきます。
レバレジーズで発生した抽出更新の失敗
レバレジーズでは現在、約700件のデータソースをTableau Cloud上で定期的に抽出更新しています。しかし、そのうち62件のデータソースで頻繁に更新エラーが発生していました。
失敗が発生していた状況を整理すると、以下のような傾向がありました。
- エラーが発生するデータソースは、ほぼ毎日同じものだった
- データソースの半数以上が朝7時〜9時の時間帯に更新を設定しており、この時間帯に失敗が集中していた
実際のエラーメッセージは以下です。
①Tableau Cloudのジョブ画面上で表示されるエラーメッセージ
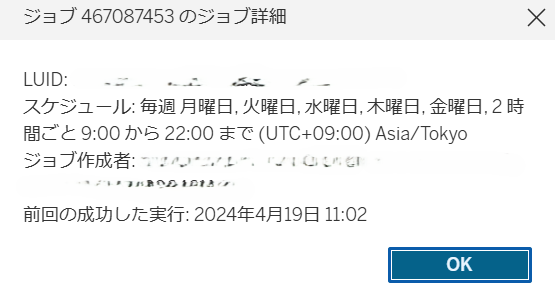
②メールに通知されるエラーメッセージ

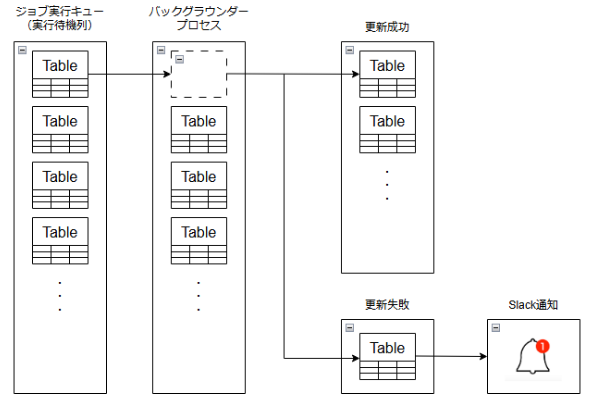
こうした抽出更新の失敗に対して、以下のような手動オペレーションで対応していました。
- メールで届く更新失敗の通知をSlackに連携して即時検知
- 手動で抽出更新を再実行
- 成功/失敗を確認し、失敗していれば再度実行
- 成功するまで繰り返す
このように、人力による都度対応で日々の運用を維持していました。
しかし、こうした手動対応には以下のような課題がありました。
実際に、抽出が更新されていなかったことで、現場から毎日多数の問い合わせが寄せられ、対応に半日を費やすなど、非常に大変な状況でした。
このような状況を受けて、「そもそも抽出更新が失敗しない仕組み」づくりに着手しました。
まずは、失敗の主な要因と、それぞれに対する対処法を整理することから始めました。
なぜ抽出更新は失敗するのか
大きく分けて、抽出更新が失敗するのは以下2パターンです。
- そのデータソースが大容量のため、更新に失敗するケース
- 他の大容量データソースの影響で、巻き添え的に更新に失敗するケース
そのデータソースが大容量のため、更新に失敗したケース
前述の通り、抽出更新に失敗するデータソースはほぼ固定されており、サイズの大きいデータソースほど失敗しやすい傾向があります。
たとえば、頻繁に失敗していた「データソースA」では、
- カラム数:263列
- レコード数:8,729,810行
- ファイルサイズ:約19.9GB
という構成になっていました。
Tableau公式のヘルプにも、「データソースのサイズが10GBを超えると、抽出更新に膨大な時間がかかる」との記載があります。
明確に「10GBを超えると失敗する」とまでは記されていないものの、実際の運用では10GBを超えるデータソースで失敗が発生しやすいという実感があります。
なぜデータソースのサイズが大きくなっていたのか?
原因の一つは、「将来的に使うかもしれないカラムを念のため残していた」ことです。
Tableauダッシュボード作成時点で不要だったとしても、将来的な要件変更や現場からの改修依頼に柔軟に対応できるよう、すべてのディメンションを保持しておく設計がなされていました。
この設計は一時的には改修コストを抑えられるという利点がありましたが、データ量の増加に伴い、抽出更新に支障をきたす原因となってしまいました。
つまり、「可変性の高さ」が「運用性の低下」に転じてしまった状況です。
他の大容量データソースの影響で、巻き添え的に更新に失敗したケース
Tableauでは、同時に実行可能な抽出更新ジョブの数に上限があります。
(ライセンス形態によりますが、一般的には10〜25件程度)
サイズの大きいデータソースの抽出更新に時間がかかっている場合、
待機中の他のデータソースが更新の順番を待ちきれずにタイムアウトし、失敗することがあります。
このように、「直接の原因ではないが、同時刻に重たいジョブが走っている」というだけで、他のデータソースが巻き添え的に失敗するケースが多く見受けられました。
抽出更新の失敗を無くすための対処法
上記の抽出更新の失敗を無くすために、暫定対応と恒久対応に分けて実施していきます。
- 暫定対応
- データソースのレコード数・カラム数の削減
- データソースの抽出更新時間帯の分散
- 恒久対応
- データアーキテクチャの再設計
暫定対応は、更新失敗を一刻も早く無くすための処置としてすでに対応済みです。
恒久対応は、ここから半年ほどかけて対応予定です。
以下に対応方法の詳細を記載していきます。
暫定対応:データソースのレコード数・カラム数の削減
1. データソースごとにサイズ確認
データソースのサイズが大きいものから更新失敗を減らしていく必要があったため、まずはデータソースごとのサイズを確認して大きい順に並べ替えました。
select table_schema, table_name, round(total_logical_bytes / 1024 / 1024, 2) AS size_mb from `your_project.region-us`.INFORMATION_SCHEMA.TABLE_STORAGE where table_schema like '%your_dataset%' order by size_mb DESC;
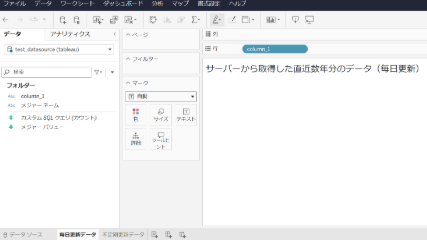
2. データソースごとにTableauでの可視化に必要な期間の絞り込み(=レコード数の削減)
Tableauでの可視化において、各データソースが保持するレコード数を削減するため、必要最低限の期間に絞ってデータを表示する対応を行いました。
まず、Tableauのワークシート上でどの程度の期間のデータを表示する必要があるかを利用者にヒアリングし、それに基づいてデータソースごとに絞り込み条件を適用しました。たとえば、以下のようなクエリで直近3年間に絞っています。
date(date_column_name) >= date_sub(current_date(‘Asia/Tokyo’), interval 3 year)
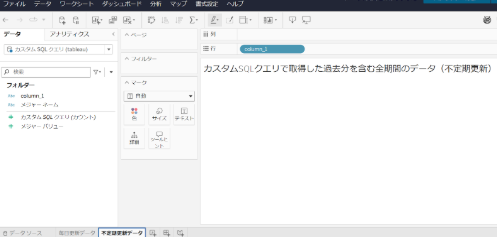
一方で、「毎日更新は不要だが、月に1回程度の頻度で過去のデータを確認したい」というニーズにも対応するため、全期間のデータを参照する専用のワークシートとカスタムSQLクエリも新たに作成しました。
具体的には、サーバー上で管理している元のクエリをTableauのカスタムSQLとしてコピーし、その中から期間を限定していた where句のみを削除することで、全期間のデータを取得できるようにしています。
このようにデータの使い分けを行うことで、通常は軽量なデータ抽出で運用しつつ、必要に応じて過去データも確認可能な構成とし、抽出更新にかかるシステム負荷の軽減を実現しました。
3. データソースごとに不要なカラムの削除(=カラム数の削減)
期間の絞り込みだけでは更新失敗が解消されなかった一部のデータソースに対して、Tableau上で表示や結合に使用されていない不要なカラムを削除し、カラム数の削減を行いました。
削除にあたって確認すべきポイントは以下の通りです。
①ワークシート上で使用されていないフィールドかどうか
すべてのワークシートにおいて、列・行・フィルターなどに使われていないフィールドを削除対象としました。
この確認にはTableauのメタデータAPI(GraphiQL)を使用し、以下のようなクエリで依存関係を調査しました
{ datasources(filter: {name: "your_datasource_name"}) { name fields(filter: {name: "your_colomn_name"}){ downstreamWorkbooks{ name } downstreamFields { name id } } } }
②データブレンド時の結合キーとして使用されていないか
プライマリデータソースとセカンダリデータソースのブレンドにおいて、結合キーとして使用されているかどうかも本来は確認すべきですが、GraphiQLではこの情報を取得できなかったため、結合キーの使用有無は目視での確認が必要となります。
ただし、レバレジーズでは今回の対応において、結合キーの確認は実施せずカラム削除を行いました。
理由は、今後別途、データアーキテクチャの再設計を予定しており、現時点でこの調査に多くの工数を割く必要はないと判断したためです。
現在は、実際に不具合が発生した際に都度修正対応を行う運用を取っています。
暫定対応:データソースの抽出更新時間帯の分散
1. データソースごとの抽出更新時間帯の確認
GraphiQLを用いたメタデータの取得では、抽出更新の「スケジュール設定時間」自体は取得できないため、代わりに最終更新時刻(extractLastUpdateTime)を利用して、大まかな実行タイミングを把握しました。
使用したGraphQLクエリは以下の通りです。
{ datasources { name extractLastUpdateTime createdAt hasExtracts } }
2. データソースごとの抽出更新時間帯の最適化
次に、Tableauのワークシートが毎日何時までに更新されている必要があるかを各利用者にヒアリングした上で、抽出更新のスケジュールを最適化しました。
特に、抽出更新の失敗頻度が高かった62件のデータソースについては、更新タイミングが重ならないよう、6:30〜11:00の時間帯に均等に分散させる設計に変更しました。
分散設計の具体ルールは以下です。
- 同時に抽出更新を開始するデータソースを5件以下に設定する
- サイズの大きいデータソース同士は同時に更新を開始しない
- 抽出更新を開始したら、他のデータソースは15分間更新を開始しない
この対応により、一時的ながらも抽出更新の失敗率を大幅に低減することができました。
恒久対応:データアーキテクチャの再設計
上記の暫定対応のみの場合、いずれデータ量がさらに多くなった際に更新失敗が発生してしまうので、恒久対応としてデータソースのサイズが大きくなりにくいデータの持ち方に変更しようと考えています。
データの持ち方を変更するにあたって、データアーキテクチャ設計自体を見直すことで持続可能なデータ分析基盤を構築していく予定です。
データアーキテクチャは、以前田代が投稿した記事『データ分析基盤再構築への道!~レバレジーズの挑戦~』や、鵜飼が投稿した記事『データ分析基盤再整備プロジェクトの全貌』と同じ思想に基づいて設計していく予定なので、詳細はそちらをご覧ください。
おわりに
データソースの更新失敗は、現場に与える影響が非常に大きく、実際に私のもとには、データを活用して意思決定を行う社員の方々から多くの問い合わせが寄せられました。
一見するとトラブルのように見えるこの出来事でしたが、社内におけるデータ利活用が着実に浸透していることを、改めて実感するきっかけにもなりました。
データが“インフラ”として根付きつつある今、この流れを止めることなく、持続可能なデータ基盤を構築・運用できるよう、引き続き改善と対応に努めていきます。