はじめに
こんにちは。レバレジーズデータ戦略室 データアーキテクトグループの辰野です。
前回、「初めてのCloud Composerのコード作成で躓いたこと」という記事を投稿し、そこでは「Cloud ComposerでDataformのワークフローを実行するコード」を紹介しました。その中で、これからやることとして記載していた「Tableauのデータ抽出更新を行う処理を組み込む」点について実装が完了したので、今回ご紹介できればと思います!
データウェアハウス層のデータ更新~BIツールのデータソース更新方法を迷われている方にとって、少しでも参考になれば幸いです!
今回実装した内容
今回の実装では、レバレジーズがBIツールとして主に利用しているTableauの、データソース抽出更新処理の組み込みを行いました。
元々、過去の記事(【Google Cloud活用事例】データマート更新~BIツールデータ更新までを自動化!)で、WorkflowsとCloud Functionsで実装していることを紹介していましたが、この内容をCloud Composerに移管するイメージです。
Cloud FunctionsでもPythonを利用してデータソース抽出更新処理を実装していたので、ほぼ転用できるといえばできますが、一度もリファクタリングを行っていなかったことと、Cloud Composerの特性も考慮する必要があったため、設計内容の見直しから行うことにしました。
設計
ワークフローの簡易的な設計は下図です。
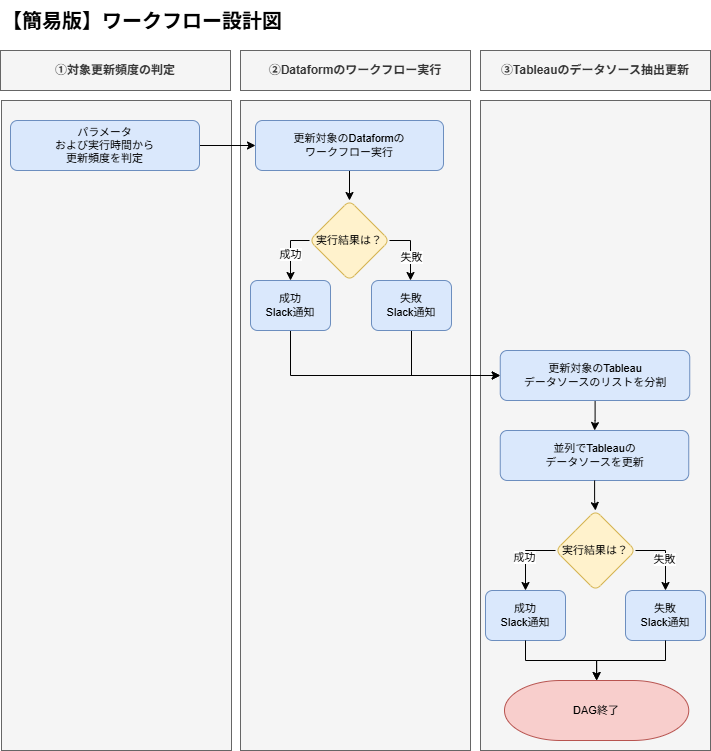
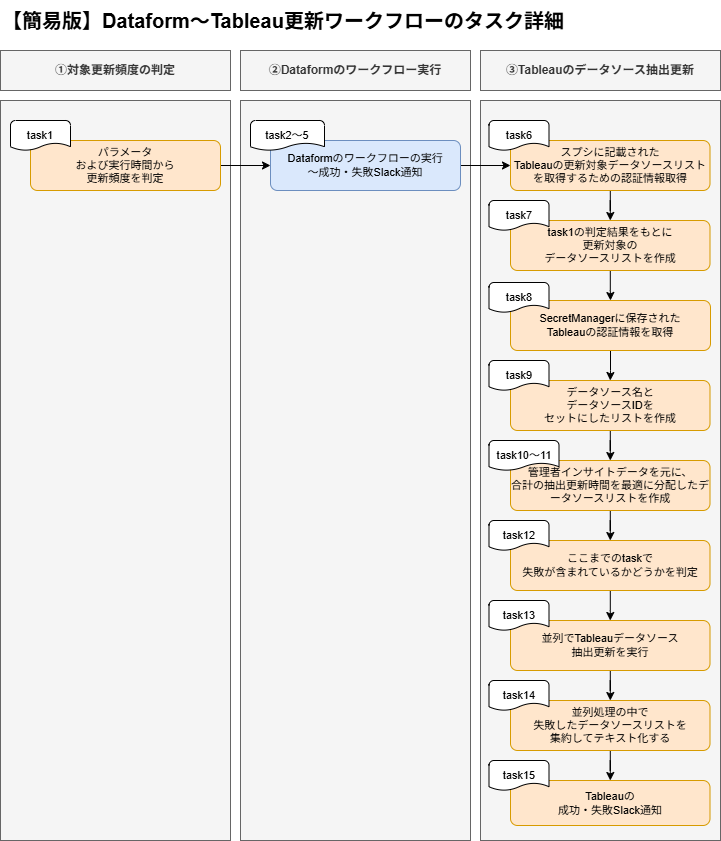
また、タスク分解は下図のようにしました。
全体を通して意識した点は、「1タスクにつき、1つの処理にすること」です。
処理を分けることで、コードの可読性が上がって保守運用しやすくなり、またエラー箇所の特定もしやすくなります。
次の項目で、オレンジ色のタスクについて、工夫した点について詳しく説明していきます。
工夫した点
タスクごとに、工夫した点について記載します。
- task1:パラメータおよび実行時間から更新頻度を判定
- ある事業部では、各テーブルを「2時間おき」「日次」の2パターンの更新頻度で更新させるようにしています。こうすることで、不用意に高頻度で更新させることによるスキャン量の増加を避けることができます。また、手動で実行する可能性も考え、パラメータ*1 の機能を利用し、更新頻度を手動で付与できるようにしました。
#### パラメータの使用例(変数名の記載は割愛) # 日次または2時間おきに実行するタスクかどうかを判定する関数 def is_updated_2h(dag_run=None, params=None): job_hour = dag_run.start_date.hour params = params.get("is_updated_2h") # RUN_IDから手動実行かスケジュール実行かを判定する run_id = dag_run.run_id is_manual = "manual__" in run_id print(f"[is_updated_2h]params={params},run_id={run_id}") # 手動実行の場合 if is_manual: print(f"[is_updated_2h]手動実行パラメータ<{params}>で実行します") return params # スケジュール実行で日次更新時間の場合 if job_hour == DAILY_JOB_HOUR: print(f"[is_updated_2h]スケジュール実行パラメータ<False>で実行します") return False # スケジュール実行で2時間おき更新の場合 else: print(f"[is_updated_2h]スケジュール実行パラメータ<True>で実行します") return True ~~~~~~~~~~~省略~~~~~~~~~~~ # DAGの定義 with DAG( ~~~~~~~~~~~省略~~~~~~~~~~~ params={"is_updated_2h": Param(True, type="boolean")}, # 2時間おき更新かどうかのパラメータを付与する ) as dag:
- task6:スプレッドシートにアクセスする認証情報の取得
- Dataformではファイルごとにつけたタグを利用して更新頻度を判別することができますが、Tableauのシステム側の機能だけでは判別するための情報が不十分でした。そこで、スプレッドシートに必要な情報を入力し、それを読み込んで更新対象リストを取得するようにしました。
- task7:更新対象のデータソースリストを作成
- task8:Tableauにアクセスする認証情報の取得
#### SecretManagerへの認証情報の登録例 user_name: 'hoge@hoge.jp' # 個人用アクセストークンを発行したアカウント site_id: 'hogehoge' version: '3.23' site_url: 'https://dub01.online.tableau.com' token_name: hoge_20260411 token_value: ※発行したシークレットを入力 token_name_refresh1: hoge_1 token_value_refresh1: ※発行したシークレットを入力 ~~~~~~~~~~省略~~~~~~~~~~ token_name_refresh20: hoge_20 # 並列処理の番号を照合して使用するため、1~20の番号をつけて発行する token_value_refresh20: ※発行したシークレットを入力
- task9:データソース名とTableauのデータソースIDをセットにしたリストを作成
- task10~11:更新対象データソースの合計の抽出更新時間を最適に分配したリストを作成
- 元々は更新対象のデータソースが少なかったことから、20並列で時間に余裕がある状態で完了していたのですが、事業拡大とともにダッシュボードが増加し、データソースの数も増えたため、更新時間の最適化を行う必要が出てきました。そこでリファクタリングをした結果、実行時間を約30分削減することができました。
- やったこととしては、リストの負荷分散です。20並列でデータソース更新を行うためにデータソースを20個のリストに分割しますが、単純に振り分けると「1つのリストに抽出更新時間が長いデータソースが集中する可能性」があり、仮に1つ20分かかるデータソースが3つ含まれているとしたら「20分経過→その後次のデータソースを更新→20分後次のデータソースを更新…」となり、これだけで60分経過してしまいます。これを防ぐために、下記を行いました。
- ① Tableauの管理者インサイト*3のデータを利用し、データソースごとの直近の平均更新時間をダッシュボード化(※TableauのAPIだけではデータソースIDごとのジョブ履歴を取得することが難しかったため、管理者インサイトのデータを使ったダッシュボードを作成してアクセスするようにしました)
- ②ダッシュボードのデータを読み込み、データソースIDを照合して平均更新時間を取得
- ③データソースIDと平均更新時間のリストを作成
- ④リストあたりの上限を設定し、平均更新時間が短いデータソースから振り分けていく
- ⑤すべてのリストの平均更新時間合計が上限に達してしまった場合は、最も合計時間が短いリストに追加する
- task12:ここまでのタスクの失敗有無の判定
#### ここまでのタスクに失敗が含まれているかどうかを判定する例 # Tableau更新タスクまでのタスクに失敗が含まれているかどうか確認する関数 def check_all_except_parallel_success(**context): """ ## 内容 - Tableau更新タスクまでのタスクで、失敗やアップストリームエラーが発生していないかを検知する - 検知された場合、次のTableau更新タスクをスキップさせるために、Falseを返す - 本関数はShortCircuitOperatorにより呼び出され、返り値がFalseの場合は次のタスクをスキップする ## 目的 - Tableau更新タスクまでのタスクでエラーがあった場合、Tableau更新タスクを実行させることは適切ではないため、スキップさせるためのもの - また、本関数の結果がFalseであればTableau更新タスクが実行されなくなるため、後続のappend_errors_taskも不用意に実行されないようにするもの """ # 検知対象のタスクを指定 tasks_to_check = [ "hogehoge", "fugafuga", ] # 返り値の初期値を指定 all_success = True # 各タスクのステータスで成功以外があるかをチェックし、成功以外があればFalseを返す for task_id in tasks_to_check: task_instance = context["dag_run"].get_task_instance(task_id) task_state = task_instance.state if task_state != "success": print(f"[check_all_except_parallel_success]{task_id} state: {task_state}") all_success = False break return all_success ~~~~~~~~~~省略~~~~~~~~~~ # Tableau更新タスクまでのタスクに失敗が含まれているかどうか確認するタスク check_all_except_parallel_success_task = ShortCircuitOperator( task_id="check_all_except_parallel_success", python_callable=check_all_except_parallel_success, trigger_rule=TriggerRule.ALL_DONE, provide_context=True, )
- task13:Tableauのデータソース抽出更新を並列で実行
- 今回は、並列処理をさせるためにDynamic Task Mapping*6を使用しました。これを使用すると、同じタスクを動的に複数回実行したり、引数ごとにタスクを並列実行したりできます。ここでは、並列処理ごとにtask8で取得したそれぞれのTableau認証情報を使用する必要があるため、Dynamic Task Mappingを使用した際に取得できる「map_index」を活用し、その番号を照合して認証情報を取得するようにしました。活用時の注意点としては「map_index」は0から始まるという点です。
#### Dynamic Task Mappingと「map_index」を使用した例(変数名の記載は割愛) # Tableauのデータソースを更新するための関数 @task def parallel_refresh_tableau_datasource(**kwargs): """ ## 内容 - 並列処理にて、引数で渡されたデータソースIDのリストを元に、Tableauのデータソースを更新する - データソースの成功・失敗を確認し、成功した場合は成功メッセージを、失敗した場合は失敗メッセージを格納する ## 目的 - 並列処理の目的は、Tableauのデータソースを1つずつ更新すると膨大な時間がかかるため、更新時間を短縮するため - エラーを発火させずメッセージを格納する目的は、並列タスクごとに成功・失敗が分かれる可能性があり、あとでまとめて成功・失敗リストにすることで把握しやすくするため """ refresh_job_retries = 0 # リトライ回数初期値 ti = kwargs["ti"] map_index = ti.map_index # 認証トークン番号指定に使用するため、map_indexを取得 job_number = (map_index + 1) # map_indexが0から始まるので、+1して認証トークン番号を取得 datasource_ids = kwargs["datasource_ids"] print(f"[refresh_tableau_datasource]datasource_ids: {datasource_ids}") results = [] # 更新対象のIDがなければ更新処理をせず終了 if not datasource_ids: print("[refresh_tableau_datasource]datasource_idsが空なので処理を終了します") return results else: print(f"[refresh_tableau_datasource]job_number: {job_number}: リストの更新処理を開始") # YAMLファイルから認証情報を格納 context = get_current_context() tableau_credentials_info = context["ti"].xcom_pull( task_ids="load_tableau_credentials_from_secretmanager" ) site_id = tableau_credentials_info["site_id"] site_url = tableau_credentials_info["site_url"] version = tableau_credentials_info["version"] # SecretManagerから対応するトークン名とトークン値を取得 token_name = tableau_credentials_info[f"token_name_refresh{job_number}"] token_value = tableau_credentials_info[f"token_value_refresh{job_number}"] # Tableauの認証とログイン tableau_auth = TSC.PersonalAccessTokenAuth(token_name, token_value, site_id) server = TSC.Server(site_url, version) server.auth.sign_in(tableau_auth) for datasource_id in datasource_ids: print(f"[refresh_tableau_datasource]データソースID={datasource_id}の更新処理を開始") ~~~~~~~~~~省略~~~~~~~~~~ # Tableauのデータソースを更新するためのタスク parallel_refresh_tableau_datasource_task = ( parallel_refresh_tableau_datasource.partial().expand_kwargs( split_refresh_datasources_task.output ) )
- task14:全ての並列タスク完了後に、エラーリストを集約する
- 並列処理で1つでも失敗した時にDAGのエラー判定をさせてしまうと、更新が完了しているデータソースがどれであるか分からなくなってしまうため、並列タスクごとに失敗したデータソースをリストにして、ここで集約させることにしました。集約したリストは、最後にTableauの成功・失敗Slack通知のメッセージに使用します。
- また、task12のときに「後続のタスクが不用意に実行されてしまうことを防ぐために、ここまでのタスクのステータスをチェックしている」ことを記載しましたが、本タスクにはトリガールールとして「NONE_SKIPPED」を指定しています。task12でエラーがあった場合はtask13をスキップするので、このtask14が不用意に実行されなくなります。
#### すべての並列タスクが完了したあとのメッセージ集約とトリガールールの例(変数名の記載は割愛) # 全ての並列タスク完了後にエラーリストを集約する関数 def append_errors(**context): """ ## 内容 - 並列処理したTableau更新タスクの全結果を取得し、成功・失敗を確認する - 成功した場合は成功メッセージを、失敗した場合は失敗メッセージを格納する ## 目的 - 並列タスクごとに成功・失敗が分かれる可能性があるため、どこで失敗したかを把握し、後続の通知タスクに使用するため """ error_messages = [] # 抽出更新失敗リストを格納 failed_messages = [] # タスク失敗リストを格納 combined_messages = [] # すべての結果を格納 target_task_id = "parallel_refresh_tableau_datasource" dag_run = context["dag_run"] for ti in dag_run.get_task_instances(): task_id = ti.task_id # 並列処理したタスクだけ処理する if ti.dag_id == dag.dag_id and target_task_id in task_id: map_index = ti.map_index state = ti.state print(f"[append_errors]map_index={map_index},state={state}") # タスクが何らかの理由で失敗した場合は、失敗した情報を追加する if state != "success": failed_message = f"[<map_index={map_index}>: 'タスクが予期せず失敗しました({state})']\n" failed_messages.append(failed_message) # 並列処理したタスクの結果を取得する task_results = ti.xcom_pull(task_ids=target_task_id) print(f"[append_errors]all_task_results: {task_results}") if task_results: for result_list in task_results: for result in result_list: if isinstance(result, dict) and result.get("status") == "failed": datasource_name = result.get("datasource_name") print(f"[append_errors]datasource_name: {datasource_name}") message = result.get("message") error_message = f"[<{datasource_name}>: {message}]\n" error_messages.append(error_message) if error_messages: combined_messages.append("【データソース抽出更新失敗リスト】\n") combined_messages.extend(error_messages) if failed_messages: combined_messages.append("【タスク失敗リスト】\n") combined_messages.extend(failed_messages) print(f"[append_errors]combined_messages: {combined_messages}") return combined_messages ~~~~~~~~~~省略~~~~~~~~~~ # 全ての並列タスク完了後にエラーリストを集約するタスク append_errors_task = PythonOperator( task_id="append_errors", python_callable=append_errors, trigger_rule=TriggerRule.NONE_SKIPPED, provide_context=True, )
- task15:Tableauの成功・失敗Slack通知
- ここで「Tableauのデータソース抽出更新ステータスは成功か失敗か」のみをSlack通知させます。
- タスクとしては記載していませんが、DAGの成功・失敗についてもSlack通知させるようにしているため、全てのDAGが完了したらDAGの成功Slack通知も送信されます。
残る課題
現在、本ワークフローは無事に運用に乗っていますが、いくつか解決すべき課題も残っています。
- DAGのタイムアウトの検知
- 現在、DAGに設定したタイムアウトの時間に達しても、検知する仕組みがありません。機能としては提供されていないようなので、これについてはどうすべきか現在も検討中です。
- エラーハンドリングの最適化
- Tableauのデータソース抽出更新において「特定のエラーコードの場合はこうする」とある程度分岐させているものの、把握できていないコードもあるので、継続的に見ていく必要があると思っています。
- データソースの最適化
- 現在、特定の事業部だけでも100を超えるデータソースが存在しています。同時に抽出更新できるデータソース数にも限りがあるため、Tableauである限りはデータソースの精査が必須となります。以前、田代が投稿していた「データ分析基盤再構築への道!~レバレジーズの挑戦~」の記事にあるデータ分析基盤の再構築を現在も進めており、それが進めばある程度更新対象のデータソースは削減されるかと思っていますが、道のりは長そうです。
今後、これらの課題について解消した際には、また紹介できればと思います。