はじめに
こんにちは。レバレジーズでデータエンジニアをしている森下です。今回はデータ活用基盤で採用しているワークフローエンジンの移管について記載していきます。現在、移管は8割ほど完了しており、技術的な山場は全て乗り越えた段階に来ています。新旧ワークフローエンジンの使い勝手や今後の展望、ハマりどころについて記載しているので、ご興味ある方はぜひご覧ください
移管の背景
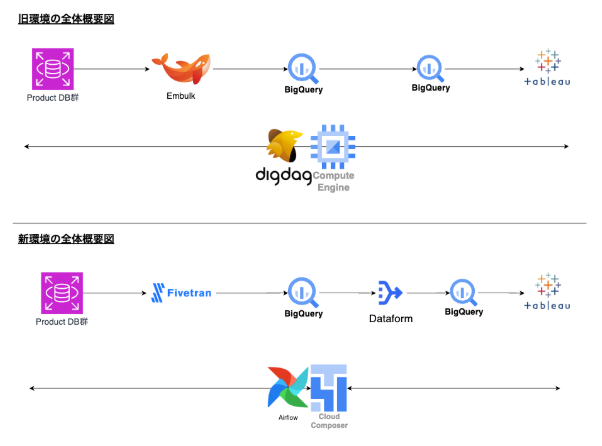
旧環境の設計・実装
旧環境の設計は約5年前に実施していました。レバレジーズは当時TreasureDataを導入しており、そこからスケーラブルな環境へ移管するためDWHをBigQueryへ移管することが決まっていました。合わせて、ETL処理やSQLワークフローの実行が必要でしたので、以下を考慮してDigdagを選定しました。
- 5年ほど前の状況では、DigdagとEmbulkを使用した構成が多く参考情報が多かった
- Digdagはワークフローをyamlで定義をし記載がシンプルであるため、データアーキテクトがSQLワークフローを載せるハードルが低かった
- 現在はDataformやdbtから実行することが多いと思いますが、5年前は素のSQLをワークフローエンジンから実行させていました
- Digdagは当時レバレジーズに導入されていたTreasureDataが開発していたOSSであった
- TreasureDataからBigQueryへ移管を計画していたため、TreasureDataで実現していたタスクをBigQueryでも再現できる可能性が高かった
TreasureDataからBigQueryへの移管についてはこちらの記事に詳細を記載しているのでご興味あればご確認ください。
https://analytics.leverages.jp/entry/2024/05/20/180000
旧環境の辛い点
これは自分の大きな反省でもありますが、あまり運用ルールをきっちり決めていなかったので、タスクによってDigdagに載せたり載せなかったり、実装方法がバラバラだったりしました。
また、何より大きな問題はDigdagを大きなGCE(Google Compute Engine)上に建ててしまったことで、スケールさせづらく、SPoF(Single Point of Failure)となって障害時の影響が非常に大きくなってしまったことです。当初は1つのデータソースからのETL処理とSQLワークフローを載せるだけの予定だったのでこのような設計にしたのですが、時間が経つにつれてデータソースが10を超えたり、連携頻度がDBごとに変更されることになったり、メタデータ収集やBI更新のタスクも載るようになったりしました。
新環境としてのCloudComposer選定
当初の想定以上に用途が肥大化してしまったため、TreasureDataへの移管が完了した段階で今後のレバレジーズの成長を見越してスケールする環境を再構築することにしました。DWHは引き続きBigQueryを使用し、ETL処理はFivetranを採用することにしました。ワークフロー部分は以下を考慮して、CloudComposerを採用することにしました
- スケールすること
- 柔軟にタスクを実行できること
- タスクの失敗の影響範囲を小さくできること
- 事例が豊富にあり、今後の機能開発にも期待できること
- 少人数で運用を回せるようにマネージドサービスであること
ワークフローエンジンの移管に関して、Fivetran移管と同時に調査を始め、昨年の4月からCloudComposerのPoCを開始しました。昨年の10月ごろより本格的に環境を構築し、Digdag上で実装していたワークフローをCloudComposerへ移管しています。
本格的にCloudComposerの使用を開始して半年ほどですが、上記の期待は合っていると感じています。
具体的な移管作業
Digdag on GCE から CloudComposer(Airflow on GKE)へ移管するにあたり、以下の改善を行いました。
インフラリソースのIaC化
5年前にDigdag環境を作った際にはコンソールから手動で構築してしまっていましたが、CloudComposerへの移管を機にインフラリソースをIaC化することにしました。いくつかの環境はすでにCloudComposerへ移管が完了していますが、既存のDigdag環境のリソースを削除するのが非常に面倒でした。また、IaC化に伴い設計と実装方針を固めたため、「どうしてこんなことに……」というような実装は今のところ発生していません。
実行環境の統廃合
移管するワークフローを精査し、ある程度の数をまとめて移管できる事業は個別の環境を構築し、少数のワークフローのみの移管になる事業部はまとめて1つの環境で実行することにしました。
開発フローの再定義と自動デプロイ
ワークフロー実装時の開発フローを整備してドキュメントにまとめました。また、GithubをGoogleCloudに接続して自動デプロイを実現し、不用意な変更が加わらないようにしました。
CloudComposerは指定のGCSへファイルをアップロードすると自動で読み込んでDAGとして認識してくれるため、Githubの特定ブランチへのマージをトリガーにGCSへファイルを転送することで自動でDAGがデプロイされるようにしました。
移管のメリット
トリガーが集約された
長年の運用の末、DigdagだけでなくCloudSchedulerにもトリガーが作成されているケースがありました。これらを移管のタイミングで見直し、CloudComposerへ集約しました。「ここを見れば全てある」 という状況を作り出すことで、認知負荷の軽減や保守工数の削減に繋がったと感じています。Githubにソースコードがあってもどこにデプロイされているかドキュメントの不足によりわからないこともあったため、そういったものが一掃されたのは運用管理において非常に楽になりました。
不要な処理を削除できた
移管に伴い既存処理を整理したことで、長年動いているが誰も保守運用できていないタスクを削除することができました。
チームの標準技術として昇華し、属人化を一定解消することができた
DigdagやEmbulkの長期運用により、システムアーキテクチャや設計思想の理解が属人化し、障害対応が職人技のようになっていました。新しい技術を導入し移管を進めることで、全員が0から技術習得を行った結果、CloudComposerを使用したアーキテクチャや設計思想をチーム全体の共通認識にすることができました。
つまずきポイント
Airflow独特の記法に慣れる必要がある
AirflowはPythonでDAGを記載しますが、Airflow独特の記法があり、最初は慣れるのが難しいです。ワークフローとして並列実行や繰り返し、成功失敗時の通知の出し分けを行いたい場合、通常のPythonとは異なる記法が多くあります。各所から「Airflowつらい」という声が漏れ聞こえてきていますが、これも独特の記法に慣れる必要があるためだと考えています。具体的なつらみについては、こちらの記事で詳しく述べています。
https://analytics.leverages.jp/entry/2025/02/18/180000
リソースのチューニングが難しい
CloudComposerはタスクの順序定義、スケジューリング、トリガーを行う役割を持っており、大量のメモリを消費するような処理はCloudRunなどの外部リソースに任せることが推奨されています。ELT処理を行う際にはCloudRunやCloudBatchを活用していましたが、CloudComposer側で時々失敗していました。外部リソースに投げてもメモリを消費することが原因の一つです。
また、並列実行のチューニングも難しいです。CloudComposer環境ではワーカーの数を指定して立ち上げ、Airflow側でもDAGを作成する際に並列実行数を指定することができます。ただし、Airflowで指定するのはあくまでアプリケーションレイヤーでの並列処理なので、ここに設定した値が大きくてもCloudComposer側のワーカー数を超える処理は並列実行できません。
実行時間が重なるとリソースを食い尽くし、DAGが失敗することがあります。これも改善すべき課題の一つです。
今後の注力ポイント
チューニングの最適解を見つけたい
複数のDAGのスケジュールを少しずつずらして実行するのはイケてないため、改善する必要があります。チューニングにはGKE側の調整も必要で、インフラ面を意識しなくてよいはずのマネージドサービスを採用したのに、自社における最適解を見つけるにはインフラ面のチューニングも求められるようです。CloudComposer3ではよりマネージドサービスとして改善されていますので、チューニングをどこまで進めるかはCloudComposer3の検証結果次第だと思います。
SREと一緒に監視を強化したい
最低限の外形監視やリトライ処理は実装されていますが、SLOやSLIの設定によるシステム管理はまだ十分ではありません。事業拡大を考えると、まずは基盤をしっかり固め、スケール可能な堅牢なワークフロー実行環境を整える必要があると考えています。
最後に
CloudComposerへ移管することで、リソースのチューニングに手間はかかりますが、Digdag運用時のインフラ管理から解放されることは大きなメリットです。また、スケーラブルな環境に移行したことで、今後の事業成長に対応できるワークフローエンジンの進化が期待できます。
レバレジーズではデータエンジニアを大募集中です。トータルで1000人以上が使用するデータ基盤の構築や機能実装を一緒に行ってくれる仲間を募集しています。興味のある方はぜひご連絡ください。