はじめに
こんにちは。データエンジニアリンググループの森下です。今回は、私がプロジェクトマネージャーとして約3年間かけて実施した、TreasureDataからBigQueryへの全社データ活用基盤移行プロジェクトについてお話します。このプロジェクトは、全社で1日あたり数千件のクエリが実行されるデータ基盤を移行するという大規模なもので、関係者の数は200〜300人に上りました。プロジェクト期間中は、データ活用基盤の技術調査から始まり、関係者への説明や調整、データ移行、クエリ移行、ETLやReverse ETLに使用する各種ツールの導入など、本当に多くのタスクがありました。
プロジェクト背景: TreasureData導入とその課題
TreasureData導入の背景
2024年時点ではGoogle BigQueryを使用していますが、その前の環境が導入された背景を説明します。 2018年12月ごろにレバレジーズではTreasureDataをデータ活用基盤として導入しました。TreasureDataが導入される以前は、各事業部が本番DBのリードレプリカを直接参照してデータ分析やモニタリング用のデータ抽出を行っており、データウェアハウスやデータマートといった概念は存在しませんでした。データを利活用する際には、一度ローカルPCにダウンロードしてからエクセルやスプレッドシートにアップロードして使用していたようです。
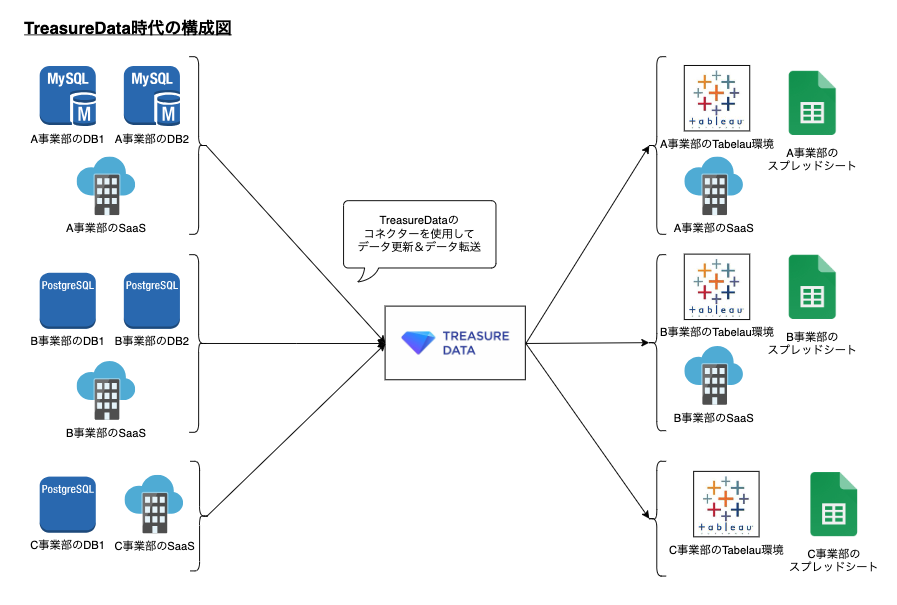
当時はデータエンジニアも社内にいなかったため、エンジニアの工数を大きく使用せずに利用できるデータ活用基盤としてTreasureDataの導入が決まりました。導入にあたっては、マーケティング部が主導して進めていったようです。TreasureDataが導入されたことによって、本番DBに直接SQLを発行することなくデータを参照できるデータ活用環境が整備されました。TreasureDataは豊富なコネクターを提供しており、認証を通せばDBやSaaSから簡易にデータを取得することができます。また、スプレッドシートやTableauへデータを出力しモニタリング環境として使用したり、MarketoやMailchimpといった外部ツールへデータを送り込み各種マーケティング活動に使用することができるようになり、多くの業務改善が進んでいきました。 SQLを書く必要はありますが、データ連携に関してはGUI操作だけで完結するため、営業やマーケターなど、エンジニア以外の職種でも簡単にデータ分析ができるようになり、データドリブンな意思決定が促進されました。
しかし、TreasureDataの利用拡大に伴い、いくつかの課題も発生しました。
TreasureData運用上の課題
2020年ごろから以下の課題が発生し始めました。
- ジョブの同時実行数上限: レバレジーズが契約していたTreasureDataのプランでは、同時実行可能なジョブ数が255に制限されていました。このジョブ数には、データ更新ジョブ、クエリ実行ジョブ、データ転送ジョブの3つが含まれます。例えば、TreasureData内のデータを使用して外部にデータを送り込む場合、クエリ実行ジョブとデータ転送ジョブでジョブ数は2にカウントされます。これにより、夜間のデータ更新ジョブが失敗していたり、外部から実行されるクエリ実行ジョブが同時実行上限に達してAPIが弾かれていたりしていました。そうなると朝に再度実行しないといけなくなり、翌日の業務に支障が出ることがありました。
- クエリ実行速度の低下: データ量とジョブ数の増加に伴い、クエリ実行時間が長くなっていきました。徐々にクエリ実行ジョブがキューに詰まるようになり、特に午前中は前日のデータを使用したデータ更新ジョブが大量に実行されるため、クエリを実行してから実行開始まで数分ほぼ待たされるような状況でした。朝イチの大事な会議で使用するTableauのダッシュボードが更新されていない、といった状況も何回か発生しました。
- 権限管理の煩雑さ: TreasureDataでは、アクセス権限をデータベース単位でしか設定できませんでした。そのため、細かい権限管理が難しく、セキュリティ上の懸念がありました。また、誰がいつどのデータにアクセスしたかを追跡するのも容易ではありませんでした。
レバレジーズは年130%成長を続けており、データ量も同様に増加しています。データドリブンな意思決定を様々な場面で行うためにTreasureDataの利用者数も増加しており、安定したデータ活用環境の重要性が増していました。上記の課題を解決し、成長し続ける事業を支えていけるようなデータ活用環境の構築が必要でした。
データ活用基盤の移管プロジェクト概要
移管前後の簡易構成図
複数事業部が同一環境を使っている状態から、事業部毎にGCP環境を分けました。
ここには載せきれていませんが、データソースはDBやSaaS以外にも、手動でcsvファイルをアップロードしているものやAPIを利用して外部からデータをインサートしているものまでたくさんのものがありました。最終的にBigQueryで更新されるようにしたデータソースの数は40ほどになるかと思います。 TableauやスプレッドシートはBigQueryと直接繋げられますが、データ転送用にコネクターを実装する必要があるものについては、自作で1つ1つ作っていきました。

進め方
TreasureDataは3つの事業部が同時に利活用している環境でした。プロジェクトを進めるにあたり、まずは1つの事業部で移管を進め、そこで得た各種ノウハウを他2事業にも転用する形で進めていきました。プロジェクトの概要は以下になります。
- DWH製品の選定: 2020年の5月ごろから情報収集と技術調査をはじめ、最終的にはBigQueryを選びました。
- ETL機構の設計と実装: 2020年の8月ごろから情報収集と技術調査をはじめ、ワークフローエンジンとしてDigdagを、バルクローダーとしてEmbulkを選定しました。これについては、既存でTreasureDataが動いていたため高価なSaaSは導入できず自前での実装が必要だったこと、当時はEmbulkを使用したデータ更新が多く事例として見かけたこと、DigdagとEmbulkはTreasureDataが開発しているOSSであったためTreasureData環境を再現するには最適であろうことが選定理由となります。
- ローデータ更新からBIツール更新までの流れをBigQueryへ移管: 2020年の11月ごろから、TreasureDataで運用していたSQLワークフローをBigQueryへ移管していきました。後述しますが、TreasureDataはSQLエンジンとしてPrestoを使用しており、 BigQueryは標準SQLを使用しているため、微妙に文法が違います。この違いを1つ1つ調べ、Prestoから標準SQLへ書き換える地味な作業をずっと行っていました。また、社内で使用する Presto⇔標準SQL の変換表を作成し、社内ユーザーに共有していました。
- BI以外の利用におけるSQLの移管: 2021年の4月ごろからBIツール以外の利用シーンにおけるSQLの移管を進めていきました。上記のBIツールに使用するデータはほぼ営業支援システムだけでしたが、BIツール以外の活用シーンでは営業支援システム以外のデータも多く使用していました。そのため、データが必要になるたびにEmbulkを使用した自作コネクターを実装し、BigQueryへデータを連携し、そこからSQLを書き換える、といった作業を行なっていました。
- 残り2事業部の移管計画立案と承認 2021年の10月ごろから残りの2事業部のTreasureDataからの移管プロジェクトの立案を始めました。最初の事業部は移管対象のSQLが500ほどでしたが、残りの2事業部は合わせて1700ほどあり、影響範囲もより広くなっていました。事業責任者へは、1つ目の事業部の実績を話しながら費用やスケジュールの承認を得たのを覚えています。
- 残り2事業部のBigQuery環境整備: 2022年の1月ごろから1つ目の事業部と同じようにワークフローエンジンにDigdag、バルクローダーとしてEmbulkを使用して、TreasureDataと同じ頻度でBigQueryにも各種システムやSaaSのデータが更新される環境を構築しました。2回目の実装であったこともあり、ここは割とスムーズにいきました。
- 2事業部のSQL移管: 2022年の5月頃からSQLの移管を進めていきました。数が膨大であること、利用者が200名を超えることもあり、非常に骨が折れる作業でした。Prestoから標準SQLへの変換ツールがこの時にはあったのですが、それを通してもうまく変換できないSQLも多く、それらは目で見て確認し、修正を加えていく必要がありました。また、TreasureDataにはデータリネージの機能がなかったため、SQLを変換してBigQuery上で実行してみて初めて足りないデータに気がつくことも多くありました。そういったものは、DB名とテーブル名しかわからないので1つ1つ管理者に連絡したり、TreasureDataのコネクターを見てどのようなデータでどうやって更新しているかを調査し、1つ1つBigQueryで同じデータを参照できるように実装していきました。
- 全てのSQL移管完了: 2023年の8月末がTreasureDataの契約終了日でした。9月からは利用できなくなりますので、絶対にそれまでに移管を完了させる必要がありましたが、多くの方のご協力のおかげで無事に移管が完了しました。
なぜBigQueryを選んだのか?
BigQueryを選んだ理由はいくつかありますが、大きくは以下になります。
- Googleスプレッドシートとの親和性: レバレジーズでは、Googleスプレッドシートがデータの可視化や共有に広く活用されています。BigQueryはスプレッドシートとの連携機能が充実しており、データ分析結果を容易に共有できる点が魅力的でした。
- Google Workspaceとの連携: Google Workspaceを利用しているため、BigQueryとの連携により、ユーザー管理や権限管理を効率化できると考えました。特に、退職時の権限剥奪など、セキュリティ対策を容易に実施できる点がメリットでした。
- 管理工数の削減: BigQueryはサーバーレスアーキテクチャを採用しており、インフラの管理が不要です。また、課金体系もシンプルであるため、データエンジニアの管理工数を削減できると判断しました。
- 性能と拡張性: 増加し続けるデータ量やジョブ実行数に対して自動でスケールアップする環境があることも魅力でした。
BigQuery移行による改善点
BigQueryへの移行により、TreasureDataで抱えていた課題を解決し、以下の改善を実現しました。
- クエリ実行速度の向上: BigQueryの高い処理能力により、クエリ実行速度が平均2〜10倍向上しました。これにより、データ分析にかかる時間が大幅に短縮され、業務効率が改善しました。以前は、多くのユーザーが利用する午前中はジョブがキューに入ってしまうことが多かったですが、そういったことは無くなりました。
- 同時実行ジョブ上限の撤廃: BigQueryでは、同時実行可能なジョブ数に制限がないため、TreasureDataで発生していたジョブ詰まりが解消されました。特に夜間に実行されるバッチ処理が安定するようになり、データ更新の信頼性が向上しました。
- ストレージ容量の拡大: BigQueryはペタバイト級のデータを保存できるため、日次スナップショットデータを蓄積できるようになり、今までできなかった分析や機械学習モデルの実装が可能になりました。
- 細かな権限管理: BigQueryでは、テーブルやカラム単位でアクセス権限を設定できるため、業務範囲に応じた適切なアクセス制御が可能になりました。これにより、機密情報の漏洩リスクを低減し、セキュリティを向上させることができました。また、実行ログを詳細に取得できるため、誰がいつどのデータにアクセスしたかを把握しやすくなり、不正アクセスなどの対策も容易になりました。
- データリネージの可視化: DataformやDataplexなどのツールを活用することで、データの流れを可視化し、データの品質管理やトラブルシューティングが容易になりました。特に、システムリプレイスの際には、影響範囲を迅速に特定できるようになり、移行作業がスムーズに進みました。
その他の点も加えてまとめると以下の表になります。
| 項目 | TreasureData | BigQuery |
|---|---|---|
| クエリ実行速度 | ものによるが1時間以上かかるものもあった | 多くの場合で2〜10倍高速化し、長くても5分ほどで完了するようになった |
| 同時実行ジョブ上限 | 255を超えるとエラー | 制限なし |
| ストレージ容量 | 保有レコード数の上限あり | なし |
| アクセス権限 | DB単位 | テーブル・カラム単位 |
| ログ追跡 | API利用してログを別途取得 | Cloud LoggingやBigQuery上で検索可能 |
| データリネージ | 可視化機能なし | Dataform, Dataplexで可視化 |
| 外部ツールとのデータ連携 | コネクターが豊富でコンソールからの操作のみで可能 | 別途実装が必要 |
プロジェクトにおいて苦労したポイント
大きく2つの苦労したポイントがあります。
標準SQLとPrestoの違い
社内で日常的に使用されていた約2,200件のクエリをTreasureDataからBigQueryへ移行する作業は、プロジェクトの中で最も大変なものでした。 Prestoと標準SQLの違いで苦労した点をいくつかご紹介します。
- 曜日の関数: TreasureDataの
day_of_week()と 標準SQLのdayofweek()とでは、返される値が1日ずれるため、調整が必要でした。- day_of_week()
- 1~7が返却される(月曜=1、日曜=7)
- DAYOFWEEK()
- 1~7が返却される(日曜=1、土曜=7)
- day_of_week()
- 独自関数の置き換え: TreasureDataの独自関数をBigQueryで実現するために、新たなロジックを構築する必要がありました。
- td_ip_to_country_name: IPアドレスから国を判定する関数は、BigQueryでは提供されていないため、独自に実装しました。
- td_time_range: 日付範囲の指定方法が異なるため、クエリの書き換えが必要でした。
- BigQueryで該当する関数はbetweenになるのですが、微妙に仕様が異なります。
- td_time_rangeは A ≦ time < B という比較になるのですが、between はA ≦ time ≦ B という比較になります。
- min_by()、max_by(): 当時はBigQueryでこれらの関数が使えなかったため、
ROW_NUMBER()関数などを利用して代わりの方法で実装する必要がありました。 - NULLの優先順位: TreasureDataでは
ORDER BY句のデフォルトがNULLS LASTであるのに対し、BigQueryではNULLS FIRSTであるため、ソート結果が異なる場合がありました。これにより、クエリの書き換えが必要になり、特に特定のデータを抽出するクエリで問題が発生しました。 - date_diff()の計算方法: TreasureDataでは unixtimeに変換後、差分を日に戻して計算しているようでした。BigQueryの場合はdate_diff()に指定した粒度(dayやmonth、yearなど)だけを見て計算されます。yearを指定した場合、西暦だけの差分を出してしまうのですが、誕生日が来ていない人の年齢の計算がずれてしまうので、そこを考慮した実装が必要でした
- 例:誕生日が1990/12/31 の人に対して、2024/05/01時点の年齢を計算すると、BigQueryでは 2024-1990で34歳の計算になる。
データリネージの把握
BigQueryで INFORMATION_SCHEMA.JOBS から参照できる実行ログから参照先のテーブルを確認することができますし、Dataplexを利用してデータリネージを確認することでデータの流れを可視化し、どのクエリがどのテーブルに依存しているかを把握することが簡単にできます。 TreasureDataでは、上記のような機能がなかったため、SQLを読まないとどのDBのどのテーブルからデータを参照しているか分かりませんでした。SQLの移管にあたっては、Prestoから標準SQLに変換したSQLをBigQuery上で動かして初めて足りないデータがあることに気がつくことも多かったです。 足りないデータとしては以下のようなものがありました。
- csvをローカルPCから不定期にアップロードしているデータ
- スプレッドシートで管理しているマスタデータ
- 個人が作成したスケジュールクエリで更新されるテーブルデータ
- 外部からAPIを使用してインサートされるデータ
- ローカルPCやサーバー上で動いているスクリプトからアップロードされるデータ
- 外部から実行されるSQLで更新されるテーブルデータ
今後の展望
TreasureDataからBigQueryへ移管が完了したことにより、記載してきたような多大なメリット得ています。 最初に構築したETL機構はもう4年ほど前に実装したもので、今見るとリプレイスしたい箇所が多くあります。また、メタデータ収集および活用を始めとするデータマネジメント体制構築もよく見るトピックになりました。そういったものを鑑みて、今後は以下に注力する予定です。
- Dataplexを中心としたデータマネジメントの強化
- Geminiとの連携によるデータ民主化の促進
- ワークフローエンジンのCloudCompsoer移管による可用性向上
- ELT処理のFivetran移管による更新頻度向上やELT処理のメンテナンス工数削減
- 事業部とのSLOやSLA策定を目標としたデータ活用におけるモニタリング体制構築や技術選定の基準づくり
- データ活用基盤に関連したインフラ基盤のIaC化
データエンジニアリングの分野は進歩が早く、新しい技術も多く誕生しており、トレンドの移り変わりも早いです。そういった世の中の流れに乗りつつ、データドリブンな意思決定を実現し続けるために全社で1000人以上が日常的に使用するデータ活用基盤を進化させていきたいと思います。
メンバー募集のお知らせ
弊社のサービスをデータで成長させてくれるメンバーを常時募集しています。
今回のデータ基盤で扱っているサービスは以下の通りです。
サービスとデータ基盤のテクノロジーの両方に関心を持っていただけると幸いです!