こんにちは、データ戦略室アナリティクスグループ リーダーの丸山です!
最近GoogleCloudのデータエンジニアリングに関するサービスの違いを改めて整理したいと思い、「改訂新版 Google Cloudではじめる実践データエンジニアリング入門」という本を読みました。GoogleCloudで分析基盤を構築する上で、必要なサービスの説明を1つ1つ丁寧にしている良書でした。
そこで今回は、書籍の内容を自分なりに整理しながら、アナリストの目線で便利だと思ったサービスを紹介します。具体的には、GoogleCloudの主要なデータエンジニアリングサービスであるDataform、Dataflow、Cloud Composer、Cloud Data Fusionについて、それぞれの特徴や用途を初学者の方にもわかりやすく解説したいと思います。
GoogleCloudのデータエンジニアリングの主要サービス
GoogleCloudには、データエンジニアリングの様々なニーズに対応できる、以下の主要なサービスがあります。
- Dataform: BigQueryにおいてSQLでのデータ変換ワークフローを効率的に開発、管理するためのサービス
- Dataflow: 大規模なストリームデータやバッチデータを統合的に処理するための、サーバーレスなマネージドサービス
- Cloud Composer: Apache Airflowをベースとした、フルマネージドなワークフローオーケストレーションサービス
- Cloud Data Fusion: コード不要のGUIで、多様なデータソースからのデータ統合パイプラインを構築・管理できるサービス
各サービスの特徴と用途
Dataform
Dataformは、主にBigQuery内でSQLを用いてデータ変換を行うことに特化したサービスです。SQLを拡張したSQLXファイルやJavaScriptを使って、複雑なデータ変換処理を記述できるのが大きな特徴です。特にJavaScriptを利用することで、複数オブジェクトで共通して使うカラムを再利用しやすくなります。
Dataformで利用されるSQLXファイル内には、大きくconfigブロックとbodyブロックが存在します。configブロックでは出力テーブルタイプやカラム名などのメタデータを管理することができます。bodyブロックでは主にSQLを定義します。configブロックでdependencies、またはbodyブロックでref()関数を使用することで、データ変換の依存関係を管理することができます。
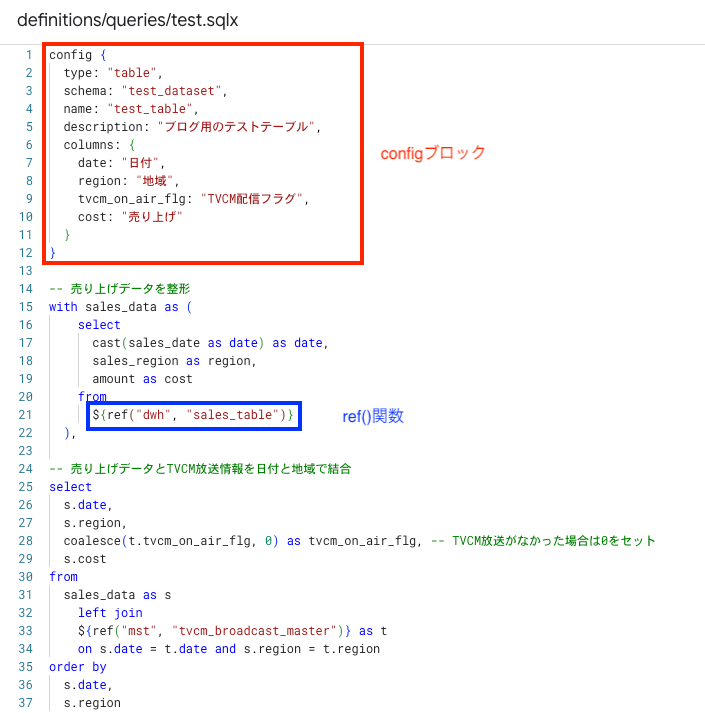
開発の流れとしては、まずGitに連携されたリポジトリを作成し、その中で隔離された開発環境(ワークスペース)で作業を行います。コードを記述したら、標準SQLにコンパイルを行い、BigQuery上で依存関係に基づいた順序で実行します。このように開発・チームでの共同作業・実行までをサポートするウェブベースの統合開発環境(IDE)を提供しているのもDataformの特徴です。
用途:
Dataformの主な用途は、BigQueryのデータウェアハウス内で、分析やレポート作成に必要なデータモデルや変換ロジックを構築・管理することにあります。具体的には、テーブルやビュー、そして差分のみを更新する増分テーブルなどを作成可能です。これに加えて、依存関係に基づいて変換が正しい順序で実行されるように、BigQuery内でのELTパイプラインを編成する役割も担っています。BigQueryとの連携が非常に強いため、BigQueryを積極的に利用しているユーザーにとって、データ変換処理に特化した強力なサービスと言えます。そのため、SQLに慣れているデータアナリスト・データアーキテクトの方が多い環境では、特におすすめできるサービスです。
Dataflow
Dataflowは、Apache Beamというオープンソースのプロジェクトを基盤とした、フルマネージドでサーバーレスなデータ処理サービスです。大規模なストリームデータとバッチデータの両方を、統合的に処理できるのが特徴です。様々なデータソースからデータを読み込み、変換し、そして目的の場所に書き出すデータパイプラインを構築することができます。
Dataflowは、PythonやJavaなどの言語のSDKを使って、一度記述すれば様々な実行環境で動作する移植性の高いパイプラインを開発できるApache Beamの技術を利用しています。これにより、過去の蓄積データであるバッチデータと、リアルタイムに生成されるストリームデータの両方を処理することが可能です。
主な利点としては、データ量や処理負荷に応じて自動的にスケールアップ・ダウンする機能や、リソースの使用率を最適化するための処理の分配、そして信頼性の高いデータ処理を実現するための処理保証などが挙げられます。
Dataflowでは、データはDAG(有向非巡回グラフ)で表現される一連の変換ステップを通過するデータパイプラインモデルを使用します。Apache Beamは、データセットを表すPCollectionという概念と、PCollectionに対する操作を表すPTransformという概念を使って、これらのパイプラインを定義します。
Dataflowは、Pub/Sub(データの取り込みに利用)やBigQueryといった他のGoogleCloudのサービスと非常にスムーズに連携できます。また、様々な種類のデータソースや出力先に対応するためのコネクタも豊富に用意されているのが特徴です。
用途:
Dataflowの主な用途は、大量のデータをバッチ処理またはストリーミング処理するための複雑なETLパイプラインの開発にあります。Pub/Subのようなソースから入ってくるストリーミングデータに対して、リアルタイムで分析を実行する処理は前述のDataformでは実現できません。また、SQLだけでは実現が難しいような高度なデータ変換や集計処理を実装するのにも適しています。Dataflowの強みは、自動スケーリングと高い耐障害性を持ちながら、バッチ処理とストリーミング処理の両方のシナリオで大量のデータを扱える点にあります。Apache Beamに依存しているため、柔軟性と移植性は高く、シンプルなSQL変換を超える複雑なデータ処理ニーズに対応できる強力なサービスと言えます。その一方でSQL中心のDataformと比較すると、学習コストが高いというデメリットもあります。
Cloud Composer
Cloud Composerは、広く利用されているオープンソースのApache Airflowプロジェクトを基盤とした、フルマネージドなワークフローオーケストレーションサービスです。Cloud Composerにより、ハイブリッド環境やマルチクラウド環境にまたがる複雑なワークフローの作成、スケジュール設定、監視、そして管理を簡単に行うことができます。
Cloud Composerのワークフローは、Pythonコードを使ってDAGとして定義されるため、Pythonのスキルを持つユーザーであれば、タスクとその依存関係を容易に定義できます。先ほど説明していたDataflowでもDAGを用いていますが、DataflowがETLを行う用途で使われるのに対して、Cloud Composer単体ではETL/ELTジョブの開発を行うことを想定しておらず、あくまでもワークフロー制御に特化しているという特徴があります。
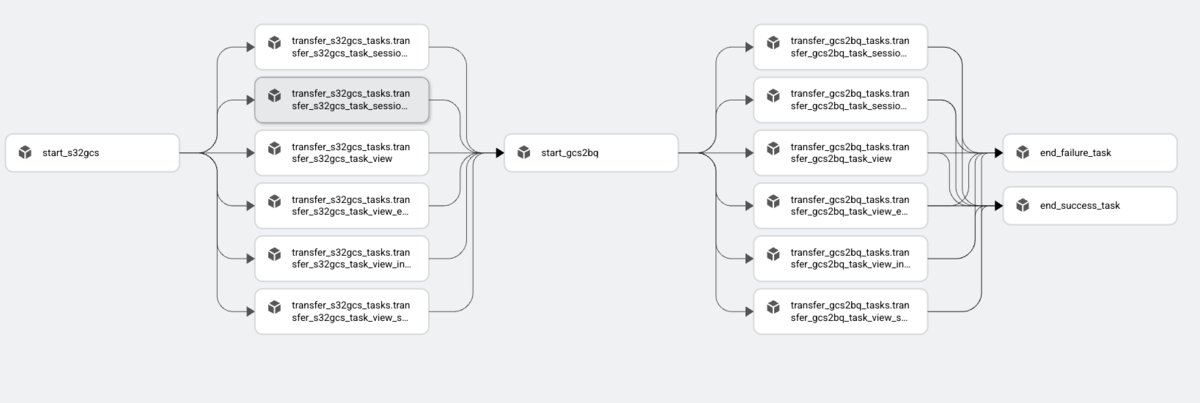
Cloud Composerでは、BigQuery・Dataflow・Dataproc・Cloud Storage・Pub/Subなど、様々なGoogleCloudのサービスや外部システムと連携するための豊富な事前構築済みコネクタライブラリが提供されています。それに加えて、ワークフローの監視と管理のための使いやすいウェブインターフェース、コマンドラインツール、そしてカスタムプラグインやPythonの依存関係をインストールする機能など、豊富な機能も提供されています。
用途:
Cloud Composerの主な用途は、複数のGoogleCloudのサービス、さらにはオンプレミスシステムを含む可能性のある複雑なデータパイプラインのオーケストレーションになります。例えば、バッチデータ処理ジョブをスケジュール設定・管理したり(タスクが正しい順序で適切な時間に実行されるようにする)、インフラストラクチャ管理タスクを実行したり、機械学習モデルのトレーニングを行ったり、さらにはCI/CDプロセスを自動化したりするのに利用されます。また、多様なワークフローを一元的に管理し、監視する機能も提供しています。このようにCloud Composerは、GoogleCloudのデータエンジニアリングエコシステムにおける中心的なオーケストレーターとしての役割を果たします。業界標準であるApache Airflowを基盤としているため、複数のサービスと依存関係を持つデータパイプラインの複雑さを管理するための、堅牢で柔軟なプラットフォームの提供が実現できています。データ自体を処理したり変換したりするわけではありませんが、DataflowやDataformなどのサービスの実行を制御する役割を担います。
Cloud Data Fusion
Cloud Data Fusionは、視覚的なコード不要のウェブインターフェースを使用して、ETL/ELTデータパイプラインを迅速に構築および管理するために設計された、フルマネージドなクラウドネイティブのデータ統合サービスです。OSSのデータパイプライン構築サービスであるCDAPが活用されています。
Cloud Data Fusionでは、リレーショナルデータベース、ファイルシステム、クラウドサービス、SaaSアプリケーションなど、幅広いデータソースに接続するための豊富な事前構築済みコネクタのエコシステムが提供されています。また、事前構築済みの変換プラグインのライブラリも豊富に用意されています。
ユーザーは、ソース、変換、シンクなどのノードをキャンバスにドラッグアンドドロップして構成することで、簡単にパイプラインを構築できます。バッチ処理のパイプラインとリアルタイム処理のパイプラインの両方を作成できるのも特徴です。
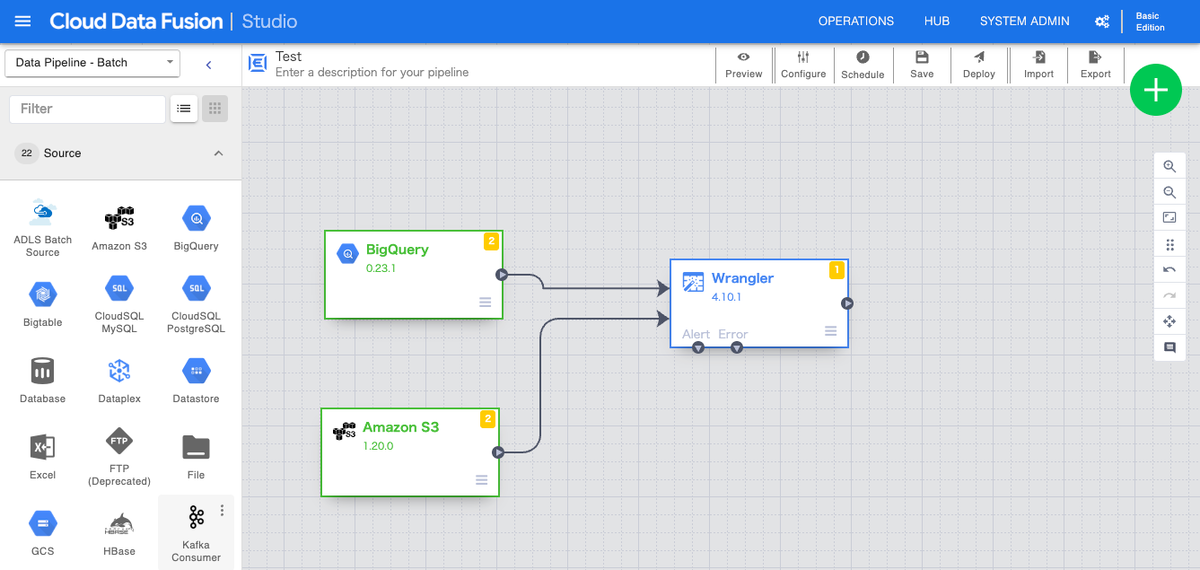
用途: Cloud Data Fusionの主な用途は、コードを一行も書かずにGUIを利用して、多様なソースからのバッチデータとリアルタイムデータのデータ統合パイプラインを構築することです。プログラミングの専門知識が限られているユーザーでも、視覚的なインターフェースを通じて、ETL/ELTプロセスを簡略化して実装できます。また、レガシーシステムと最新のシステムの両方からのデータに接続し、それらを変換するのにも適しています。さらに、一般的なデータ統合のパターンを再利用可能なデータパイプラインやテンプレートとして作成することも可能です。Cloud Data Fusionの最大の強みは、最小限のコーディングで幅広いソースからのデータに接続して変換できることであり、視覚的なアプローチを好むビジネスユーザー、データアナリスト、そして開発者にとって最適なサービスと言えます。
主な違いのまとめ
概要を明確にするために、以下の表にDataform、Dataflow、Cloud Composer、およびCloud Data Fusionの主な違いをまとめます。
機能 |
Dataform | Dataflow | Cloud Composer | Cloud Data Fusion |
|---|---|---|---|---|
| コーディング | SQLX、JavaScript | Python、Java、Go | Python | なし(GUI) |
| 主な焦点 | SQLを用いたデータ変換(BigQuery内でのELT) | スケーラブルなデータ処理(バッチ&ストリーム処理の両方に対応したETL) | ワークフローのオーケストレーションとスケジューリング | データ統合(多様なソースからのETL/ELT) |
| ユースケース | ・BigQueryデータモデリング ・データ品質とSQLの依存関係の管理 |
・リアルタイム分析 ・複雑なデータ変換(並列分散処理向け) |
・複数ステップのデータパイプラインのオーケストレーション ・GoogleCloud全体でのジョブのスケジューリング |
・様々なデータソースへの接続 ・コード不要のETL/ELT ・データラングリング |
| 基盤技術 | SQLX | Apache Beam | Apache Airflow | CDAP |
| 対象ユーザー | SQLに慣れたデータアナリスト データアーキテクト |
データエンジニア データサイエンティスト |
データエンジニア データアーキテクト ワークフロー管理者 |
ビジネスユーザー データアナリスト |
| データソース | 少ない(BigQueryにLoadされたデータのみ) | 多い(Apache Beam I/Oコネクタを使用) | なし | 多い |
| コスト | BigQueryで実行したSQLにかかるコストのみ | スクリプトの実行時間に応じて課金 | インフラ部分はGKEで構築されていて、基本的には実行させ続けることが必要 上記に伴いコンピューティング料金が発生 |
GUIで簡単に実装できるが、その分料金帯は高め |
これからGoogleCloudでデータ分析基盤を構築する方は、上記の表を参照することで、特定のニーズと技術的な専門知識に基づいて最適なサービスを絞り込むことができます。参考にしてみて下さい!
まとめ
今回はGoogleCloudでデータ分析基盤を構築する上で有用なサービスをいくつか紹介しました。
自分の職種はデータアナリストなので、このあたりのサービスに明るいわけではないのですが、書籍を読んでインプットをすることで知識の幅を広げることができました。
またこの記事では紹介できなかったのですが、GoogleCloudにはDatastreamやBigQuery Data Transfer Serviceなど、他にもデータ活用時に使えるサービスがたくさんあるので、機会があれば勉強してこのような形でまとめたいなと考えています!