はじめに
こんにちは。レバレジーズデータ戦略室、データサイエンスグループの徳田です。 データサイエンティストのみなさん、モデル開発に携わると、ビジネスサイドから「このアルゴリズムを導入したら、ビジネスにどれくらいのインパクトがあるか試算してほしい」と頼まれることが多々ありますよね?しかし、アルゴリズムの導入効果は、実際に導入してA/Bテストをしなければ正確な効果は分からないという課題もあります。
そんなときに役立つのが、「モンテカルロ シミュレーション」です。A/Bテスト前にシミュレーションを行い、ある程度のビジネスインパクトを見積もることで、施策導入の意思決定に向けた情報を提供できます。本記事では、モンテカルロシミュレーションを使ってレコメンド導入の効果を試算する方法について解説し、シミュレーション結果をビジネス上どう活かせるかを説明します。
モンテカルロシミュレーションとは?
モンテカルロシミュレーションは、複数の変動要素を含む複雑な状況でのアウトカムを予測する手法です。確率分布を用いて乱数を生成し、これを複数回シミュレーションすることで、将来のインパクトの分布や平均を推定します。この方法は、ビジネス施策の効果を「事前」に試算する際に有効です。例えば、レコメンドを導入した場合、応募数や売上がどのように変動するかをあらかじめ試算することができます。
レコメンド導入効果のシミュレーション:具体的な例
ある架空のスカウトサービスを運営する企業が、レコメンドエンジン導入による年間売り上げ増加効果を検証したいと考えているとします。このレコメンドエンジンは、企業向けであり、企業担当者が候補者を探す際に、活用して最適な候補者を提示するものであるとします。
1. シミュレーションの前提条件とパラメータ設定 シミュレーションを行うにあたり、以下のようなパラメータを設定しました。ただし、精度の高いシミュレーションを行うためには、過去のデータや業界のベンチマークに基づいて設定することが重要です。今回使用する値は全て仮の値となっております
ユーザー情報
- 新規ユーザー数:30人(1日の新規ユーザー登録数)
- 既存アクティブユーザー数:1,000人(既にスカウト媒体に登録済みのアクティブユーザー)
スカウト配信数
- 1日に送信されるスカウト数:100件
応募率とレコメンドの効果
基本応募率:8%
- スカウト受信数によって、応募率は低下するので、スカウト受信数によって応募率が変わるように設定
スカウト受信数に応じて応募率が低下するのは、ユーザーが多くのスカウトに埋もれてしまい、個々のスカウトへの関心が薄れるため
スカウト受信数 応募率 3件以下 8% 4~5件 6% 6件以上 4%
レコメンド導入による応募率向上幅:0.5%, 1%, 3%, 5%, 10%
- レコメンド機能が応募率にどれだけ影響を与えるかは、過去の類似データや実績を基に設定します。
- 企業のレコメンド使用率:5%、10%、30%、50%、80%、100%
- レコメンド機能は全企業が利用するとは限らないため、「レコメンド機能の利用率(全企業のうち利用している企業の割合)」を設定
- 利用率が低いと、レコメンド機能の効果は限定的になることが予想されるため
内定率と売上インパクト
- 応募からの内定率:5%
- 売り上げ単価:200,000円/内定
既存ユーザーのスカウト受信履歴
- 平均スカウト受信数:3件(既に3件のスカウトを受けていると仮定)
シミュレーション回数
- シミュレーション実行回数:10,000回
2. シミュレーションの手順
- スカウト割り当て: 1,000件のスカウトを、新規ユーザーと既存ユーザーにランダムに割り当てます。割り当てはポアソン分布を使ってランダムに行い、これによりユーザーごとに異なるスカウト受信数が割り当てられます。ここでは一旦ポアソン分布を設定していますが、実際の観測データから適切な分布を設定することが求められます。
- 応募数の試算: 各ユーザーのスカウト受信数と設定した応募率に基づいて、応募数を計算します。レコメンド導入時では、応募率向上幅を加味した応募率を使用します。
- 合計応募数の試算: 既存ユーザーの応募数+既存ユーザーの応募数で算出
- ステップ1〜3を10,000回繰り返し: 応募数の平均値を算出します
- 売上の計算:4の応募数から内定数を推計し、売り上げ単価を掛けて売上を計算します。
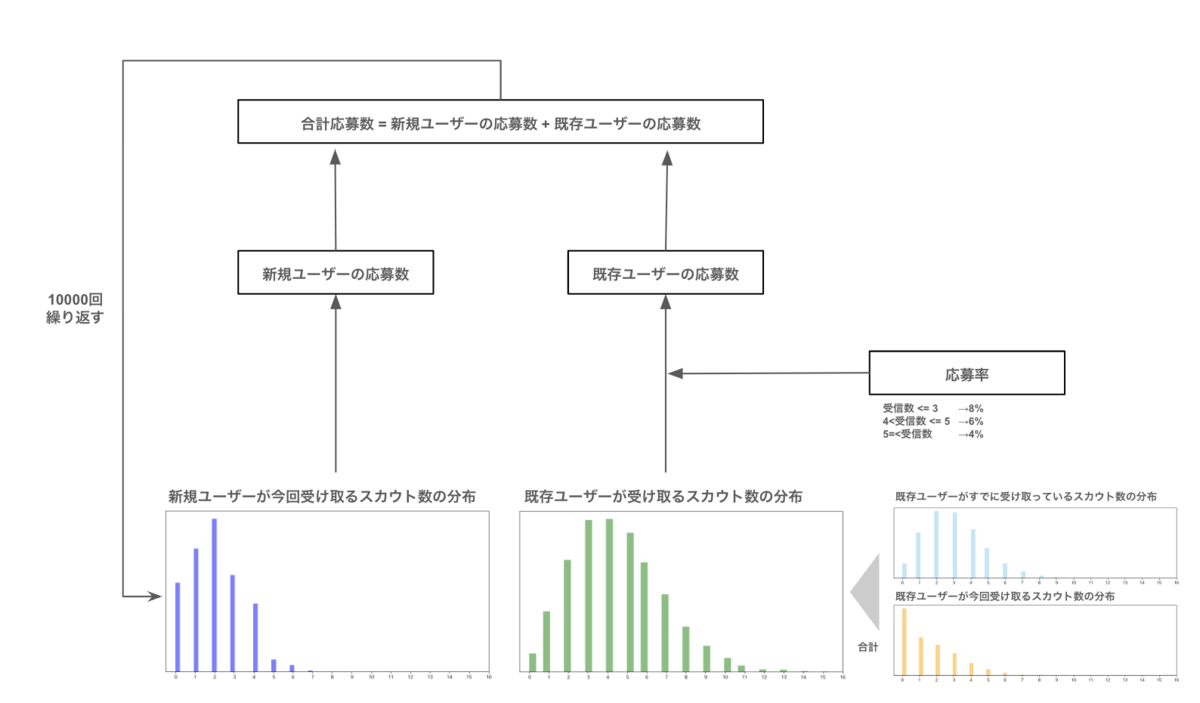
シミュレーションの手順
Pythonコードによるモンテカルロシミュレーションの実装
以下に、上記の前提条件、手順に基づくモンテカルロシミュレーションのPythonコードを掲載します。パラメータの値は今回は全て仮の値となっておりますので、実際に使う際は適切な値を当てはめる必要があります。
import numpy as np import pandas as pd import random # パラメータ設定 # 初期の条件や応募率、売上単価などを設定。 # 実際のデータに基づいて設定してください。今回設定している値は仮の値です num_new_users = 30 # 新規ユーザー数 num_existing_users = 1000 # すでに登録されているアクティブユーザー数 total_scouts = 100 # 1日に送信されるスカウト数 base_aplication_rate = 0.08 # 基本の応募率 application_to_hire_rate = 0.05 # 応募から内定率 scout_placement_fee = 200000 # 売り上げ単価 recommend_use_rates = [0.05,0.1,0.3,0.5,0.8,1] # レコメンド導入企業の割合 recommnd_add_application_rates = [0.005,0.01,0.03,0.05,0.1] # レコメンドによる応募率向上幅 past_scout_receives_num = 3 # すでに登録されているアクティブユーザーが受け取っているスカウトの平均 num_simulations = 10000 # シミュレーションの実行回数
def application_count(scout_receive_num, already_scout_receive_num, base_aplication_rate, target = None, recommend_use_rate = 0, recommnd_add_application_rate = 0): ''' ユーザーが受け取ったスカウトに基づいて応募数を算出。既存ユーザーはすでに受け取ったスカウトがあるので、それに基づいて応募率を調整する ''' rate_add = 0 if target == 'recommend': if random.random() <= recommend_use_rate: rate_add = recommnd_add_application_rate apply_count = 0 scout_count = 0 for value in range(scout_receive_num): if value >= already_scout_receive_num: # すでに受け取っているスカウトは対象外 if value <= 3: rates = base_aplication_rate+rate_add elif value <= 5: rates = base_aplication_rate*0.75+rate_add else: rates = base_aplication_rate*0.5+rate_add apply_count += np.random.binomial(1, rates) scout_count += 1 else: continue return apply_count, scout_count def adjust_scout_receives(scouts_assigned_actual, receive_scout_num): ''' 新規ユーザーが受け取るスカウト数を調整する ''' # 調整が必要な場合、合計が目標値に近づくように補正 actual_total = np.sum(scouts_assigned_actual) difference = receive_scout_num - actual_total # 必要なスカウト数の補正 while difference != 0: if difference > 0: # 差分が正の場合、ランダムにスカウト数を増加 add_indices = np.random.choice(scouts_assigned_actual, difference, replace=True) scouts_assigned_actual[add_indices] += 1 else: # 差分が負の場合、ランダムにスカウト数を減少 remove_indices = np.random.choice(np.where(scouts_assigned_actual > 0)[0], -difference, replace=True) scouts_assigned_actual[remove_indices] -= 1 # 再計算 actual_total = np.sum(scouts_assigned_actual) difference = receive_scout_num - actual_total return scouts_assigned_actual def simulate_applications(num_new_users, num_existing_users, total_scouts, target = None , recommend_use_rate = 0, recommnd_add_application_rate = 0 ): ''' 新規ユーザーと既存ユーザーのグループごとにスカウト数を割り当て、応募数を計算。 ''' receive_scout_num_new_user = int((num_new_users/(num_existing_users+num_new_users))*total_scouts) # 新規ユーザーのスカウト受信数 new_lambda = receive_scout_num_new_user / num_new_users # 新規ユーザーが受け取れるスカウト数の平均 scouts_new_assigned_actual = np.random.poisson(new_lambda, num_new_users) # 新規ユーザーが受け取るスカウト scouts_new_assigned_actual = adjust_scout_receives(scouts_new_assigned_actual, receive_scout_num_new_user) # 新規ユーザーが受け取ったスカウト数を調整 results_new_user = [application_count(scout_receive_num, 0, base_aplication_rate, target, recommend_use_rate, recommnd_add_application_rate) for scout_receive_num in scouts_new_assigned_actual] application_count_new_user, _ = zip(*results_new_user) # 各新規ユーザーが応募したかどうか past_scouts_per_user = np.random.poisson(past_scout_receives_num, size=num_existing_users) # すでに登録されているアクティブユーザーが受け取っているスカウト receive_scout_num_existing_user = total_scouts - np.sum(scouts_new_assigned_actual) # すでに登録されているアクティブユーザーのスカウト受信数 existing_lambda = receive_scout_num_existing_user / num_existing_users # すでに登録されているアクティブユーザーが今回受け取れるスカウト数の平均 scouts_existing_assigned_actual = np.random.poisson(existing_lambda, num_existing_users) # すでに登録されているアクティブユーザーが今回受け取れるスカウト scouts_existing_assigned_actual = adjust_scout_receives(scouts_existing_assigned_actual, receive_scout_num_existing_user) # すでに登録されているアクティブユーザーが受け取ったスカウト数を調整 total_scouts_existing = past_scouts_per_user + scouts_existing_assigned_actual # すでに登録されているアクティブユーザーが受け取ったスカウトの合計 results_existing_user = [application_count(scout_receive_num, already_scout_receive_num, base_aplication_rate, target, recommend_use_rate, recommnd_add_application_rate) for scout_receive_num, already_scout_receive_num in zip(total_scouts_existing, past_scouts_per_user)] application_count_existing_user, _ = zip(*results_existing_user) # 各すでに登録されているアクティブユーザーが応募したかどうか applications_new = np.sum(application_count_new_user) # 新規ユーザーのスカウト応募数 applications_existing = np.sum(application_count_existing_user)# 各すでに登録されているアクティブユーザーのスカウト応募数 return applications_new +applications_existing current_application_counts = [] # レコメンド導入前のシミュレーション for _ in range(num_simulations): current_application_count = simulate_applications(num_new_users, num_existing_users, total_scouts) current_application_counts.append(current_application_count) current_application_count_mean = np.mean(current_application_counts) print(f"現状の平均応募数: {current_application_count_mean}") simulation_result_df = pd.DataFrame() for recommend_use_rate in recommend_use_rates: for recommnd_add_application_rate in recommnd_add_application_rates: print(f"レコメンド導入企業の割合: {recommend_use_rate}") print(f"レコメンドによる応募率向上幅: {recommnd_add_application_rate}") recommend_application_counts = [] for _ in range(num_simulations): recommend_application_count = simulate_applications(num_new_users, num_existing_users, total_scouts, 'recommend', recommend_use_rate, recommnd_add_application_rate) recommend_application_counts.append(recommend_application_count) simulation_result_df = pd.concat([simulation_result_df, pd.DataFrame({ 'recommend_use_rate': [recommend_use_rate], 'recommnd_add_application_rate': [recommnd_add_application_rate], 'current_application_count_mean': [current_application_count_mean], 'recommend_application_count_mean': [np.mean(recommend_application_counts)] })]) simulation_result_df['currrent_revenue'] = simulation_result_df['current_application_count_mean']*application_to_hire_rate*scout_placement_fee*365 simulation_result_df['recommended_revenue'] = simulation_result_df['recommend_application_count_mean']*application_to_hire_rate*scout_placement_fee*365 simulation_result_df['diff_revenue'] = simulation_result_df['recommended_revenue'] - simulation_result_df['currrent_revenue']
3. 結果の解釈
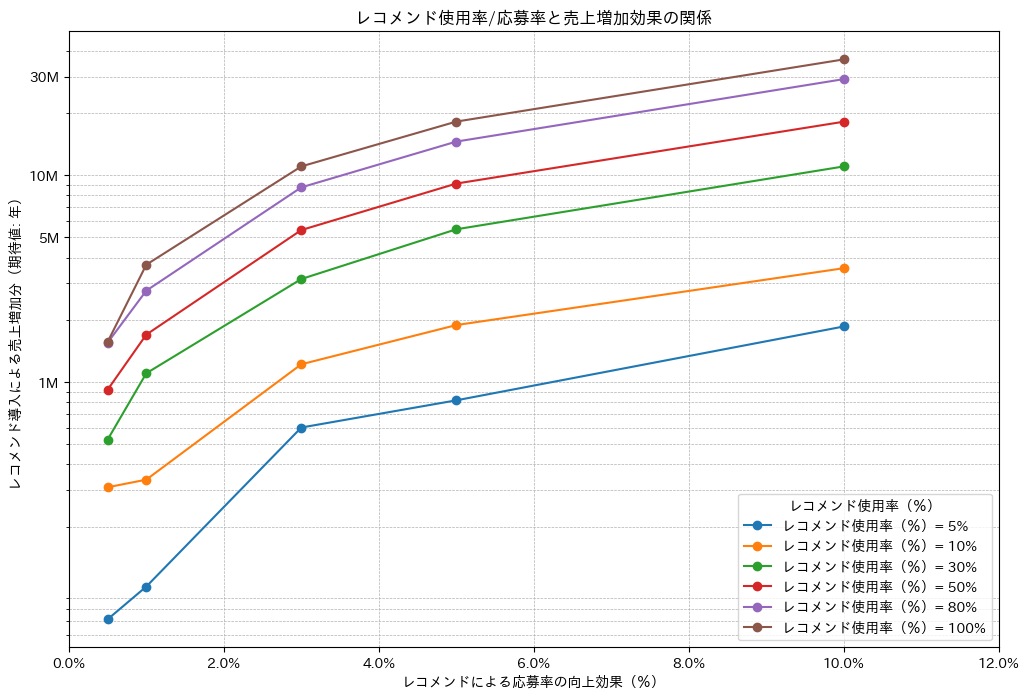
下のグラフは、モンテカルロシミュレーションによって得られた、レコメンド導入による売上増加分の期待値を示したものです。レコメンド使用率(全企業のうち利用している企業の割合)と応募率向上効果の組み合わせによって、売上増加額がどのように変化するかが分かります。例えば、レコメンド使用率が100%で応募率向上効果が10%の場合、年間約3000万円の売上増加が見込まれます。
実データに基づくパラメータ設定の重要性
モンテカルロシミュレーションの結果は、使用するパラメータに大きく依存します。したがって、応募率や内定率、売り上げ単価などの値は、できる限り実際のデータに基づいて設定することが求められます。例えば、応募率は新規ユーザーと既存ユーザーで異なる場合が多いため、各ユーザー層に適した値を設定することで、シミュレーションの精度を向上させることが可能です。
また、応募から内定に至るまでの比率(内定率)も、業界や職種、ポジションのレベルに応じて変動します。できるだけ詳細なデータを活用することで、現実に即したビジネスインパクトを算出できるようになります。
まとめ
ビジネス施策のインパクトを事前に予測することは、効率的な戦略立案や優先順位の設定に欠かせません。モンテカルロシミュレーションを活用すれば、レコメンド導入などの機能がどれだけの応募数や売上を生む可能性があるか、A/Bテスト前にある程度の精度で把握できます。しかし、シミュレーション結果はあくまで予測であり、A/Bテストを通じて検証することが必要です。この2段階のアプローチを取ることで、データに基づいた精度の高い意思決定が可能となります。