はじめに
データ戦略室ビジネスアナリティクスグループの丸山です。
最近、「データの民主化」という言葉を良く耳にします。
データの民主化とは、データサイエンティストやデータアナリストに限らず、特別な知識を持たない社員全員がデータを活用できる環境を構築することです。
データの民主化を実現するために、多くの企業は「分析基盤をどのように設計するか」「メタデータをどのように運用するか」「SQLやBIツールの使用方法など、分析に必要な言語・ツールを習得してもらうには何をすべきか」など分析に関する様々な課題に直面していることかと思います。
その一方で、分析による意思決定を全社的に浸透させるためには、「正しい示唆を得るために実施すべき分析を設計できるスキル」を社員全員が持つことも重要であると考えています。
しかし、この種のスキルについてはデータの民主化を推進するという文脈であまり触れられてないように思えます。
また、分析設計のスキルは業務のデータを触りながら実践を通して学ぶものだという風潮が強く、体系化・言語化がされていないというイメージを個人的に持っています。
私自身が上記のような課題感を持っていたため、自身がデータ分析を進める上で考えている思考内容を言語化し、弊社内に布教する取り組みを実施しました。今回はその布教内容(=データアナリストの頭の中)について共有していきたいと思います!
分析の種類について
分析の進め方の説明をする前に、事前準備として分析の種類についての話をします。
世間一般で使われている用語ではないのですが、私は分析の種類を以下の2パターンに分けて考えています。
- 知識発見型の分析
- データを見ることで、プロダクトやサービスの課題を発見するための分析
- 課題を発見した後は、その要因(すなわち仮説)を考え、後述の仮説検証型の分析を行う
- 仮説検証型の分析
- 課題がある程度明確になっている状況で、その要因についての仮説を検証するための分析
- 検証結果に応じて、施策改善をするか追加分析をするかを決めていく
上記の区分に近い考え方がこちらのブログで説明されていました。下の添付画像も同じブログから引用したものです。
以下のサイクルにおける「気づき」を得るために行う分析が知識発見型の分析、「仮説構築 ~ 仮説検証」のための分析が仮説検証型の分析となるイメージです。
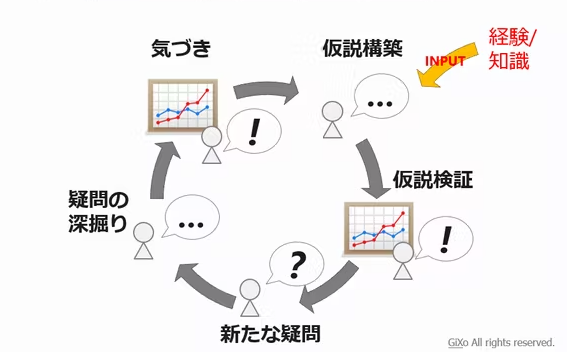
分析を進める上でのステップ
さて、準備が終わったのでいよいよ本題です。
ビジネスにおけるデータ分析は、以下のステップに基づいて進めるのが基本であると私は考えています。

- 分析の目的を設定する
- 目的達成のために、仮説や見るべき数値を洗い出す
- 知識発見型の分析の場合→見るべき数値を洗い出す
- 仮説検証型の分析の場合→仮説を洗い出す
- 洗い出した項目に対して適切に分析設計を行う
- 分析を実施する
- 分析結果を踏まえて、以下のいずれかのアクションを取る
- 知識発見型の分析の場合
- 2.に戻ってNAの分析の種類(知識発見型 or 仮説検証型)を決めた上で、分析を継続する
- 仮説検証型の分析の場合
- 施策に落とし込める示唆が出た→具体的な施策の立案に移行
- 施策の実行には情報が不十分→ステップ2.に戻り、分析を継続する
- 知識発見型の分析の場合
1.と2.の項目については、データ分析の書籍などでよく取り上げられている内容になるので、以下では「3. 洗い出した項目に対して適切に分析設計を行う」方法に絞って詳細に説明します。(社内で頒布しているドキュメントには1.と2.についての説明も記載しています。)
分析設計の方法
分析設計を行う際は、以下の事項について検討する必要があります。
- 対象期間
- 検討事項: 特殊な施策を打っている期間が含まれていないか、データが十分に確保できるか...など
- 対象ユーザー
- 検討事項: 全ユーザーに対して集計をするか、特定の条件を満たすユーザーのみにフィルタリングすべきか...など
- 使用するデータ
- これに関しては前述のステップ2.で見たい数値が決まると自動的に決まることが多くなると思います
この情報だけだと、業務でデータ分析を行う際に分析初心者がどのような問題に直面するかが分かりづらいと思うので、具体例を取り上げて説明します。
ケーススタディ: 弊社オウンドメディアのアクセスログ分析
ここでは、レバレジーズで運営しているメディアのアクセスログを用いて、「コンバージョン(以下、CV)しているユーザーとしていないユーザーのサイト内での行動差分を明らかにし、CVR向上施策を実施する」ことを目的に分析を行うケースを考えます。
上記のケースでは、CVしているユーザーとそうでないユーザーを分けて、それぞれのサイト回遊状況の基礎集計を行うことになります。
その際、CVしているユーザーはCV前のアクセスログを対象に集計する必要があります。CV後のアクセスログは、CVした結果として生じたものであり、集計しても施策に繋がらないためです。
従って、集計対象のアクセスログはCVの有無によって以下のように定義するのが良さそうです。
- CVしていないユーザー: 初回アクセス以降に遷移したページを対象に集計
- CVしているユーザー: 初回アクセス ~ CVまでに遷移したページを対象に集計
なお、対象ユーザーは直近Nヶ月に初回アクセスしたユーザーとしました。Nの値はサンプルサイズや施策などを加味して決めます。
さて、分析の設計方法について具体的に説明をしてきましたが、今回のケースでは上記の内容以外にも実は検討すべき項目があります。
下の2つの画像は、上記の分析設計に従って集計を行う場合のデータの抽出状況を図示したものです。サイトに初回アクセスした日時はユーザー毎に当然異なるのですが、それによってユーザー個別に見た場合アクセスログの集計期間にも違いが出てくる点に注意が必要です。


この設計に沿って分析を行う場合、データの傾向によっては問題が生じます。
初回アクセスから数ヶ月の間は情報収集を行い、その後CVするユーザーが大多数を占めていた場合、初回アクセス日時が遅いユーザーはCV有無の判定が適切にできません(1つ目の画像参照)。「そんなユーザーが大多数なわけないだろ!」とツッコみを入れたくなる読者の方もいるかもしれませんが、論理的に可能性がある論点は一つ一つ検証していくことを意識しています。
それに対して、CVまでの所要時間が十分に短い場合、即ちほとんどのユーザーが数時間から1日程度でCVする場合は、当初の設計に沿って分析をしても大きな問題は生じなさそうです(2つ目の画像参照)。
以上を踏まえると、今回のケーススタディにおいては「ユーザーの初回アクセスからCVまでの経過時間の分布を確認する分析」をまず最初に行い、その結果を見た上で当初実施する予定だった分析の設計を行うというのが適切な手順になることがわかります。
具体例が長くなってしまいましたが、私が伝えたかったのは「どのような意思決定をするためにどのような条件で分析を実施したか」について分析担当者が責任・根拠を持てるように分析の設計をしましょうということです。
上記で例示した通り、分析を進めていくと「集計条件を決めるために、追加で分布や数値の確認が必要となる指標」が出てきます。これらを漏れなく列挙して適切な条件で集計ができる準備をするのが肝になると考えています。
これができていないと、どんなに分析基盤が整っていても、そしてSQLを使える社員の数が増えても、分析に基づく適切な意思決定の文化が会社全体に浸透することは難しいと考えています。
適切な分析を進めるためのフレームワークの布教
上述した分析の進め方・分析設計の方法の型を身につけるために、ビジネスアナリティクスグループでは分析フォーマットの記入を習慣化しています。(添付画像参照)

フォーマットの使い方は以下のようなイメージになります。
- 分析着手前に分析内容、目的、分析手法や可視化手法、想定のNext Action(レバレジーズではNAと呼んでいる)を記載しておく
- 記載した内容に沿って分析を進める
- 分析結果 & NAを記載し、NAの分析内容を下の行に追加する
- (以下、繰り返し)
フォーマットを用いることで、「分析を進める上でのステップ」で述べたサイクルで自然に分析を進めることができます。
また、分析手法や可視化手法の記入欄を設けて第三者が見れる状況にすることで、分析設計が適切かどうかのフィードバックがいつでも受けられるようになります。
冒頭で述べた通り、このような分析の進め方のノウハウも民主化すべきであると考えているため、各事業部のビジネスサイドのメンバーにも上記のフォーマットを共有する動きも進めています。
最後に
以上が、分析の進め方や分析設計のスキルに関する布教活動の全容になります。
私が普段データ分析を行う際に考えていることを、社内のデータ分析に興味のある方々に理解してもらえたのであれば良かったと思っています!
今回のブログについては特に、データの民主化を進めたい企業のマネージャーの方や、データを使って意思決定をしたいが何から分析をすれば良いか分からない方の参考になれば幸いです。