データ戦略室で室長かつデータサイエンティストをしている阪上です。
「マーケティングサイエンス」という言葉を聞いて、その実態や面白さについてイメージがわく方はどのくらいおられるでしょうか。今回の記事では、多くの方にマーケティングサイエンスの業務について知っていただき、この業界に関心を持っていただくことを狙いとしています。
私はレバレジーズのマーケティング部門でデータサイエンティストとして働いており、マーケティングサイエンスの面白さを日々感じています。本記事では、マーケティングサイエンスの魅力や実際の活用事例を紹介しながら、この分野の魅力をお伝えします。
マーケティングサイエンスとは?
誤解を恐れずに言うと、マーケティングサイエンスは、「勝手にモノが売れる仕組みを作るための科学」と言うことができると思います。そう聞くと、何やら魔法のように聞こえるかもしれませんが、実際の実務においては、ユーザーの行動データ(アクセスログ)や営業現場の会話ログや求人提案ログ、求人情報など、様々なデータを前処理し、数理モデルに落とし込み、そこから意思決定の改善に資する示唆を引き出したりモデルを開発したりします。
使われる手法も多岐にわたります。因果推論、統計モデリング(ベイズ統計を含む)、強化学習、自然言語処理、深層学習、数理最適化など、いわゆる「データサイエンス」の総力戦と言えると思います。
たとえば次のようなテーマがマーケティングサイエンスの対象になります:
顧客の生涯価値(LTV)を予測する
営業の生産性を最大化する担当者アサインを設計する
広告の費用対効果を正確に測定し、最適な配分を提案する
レコメンドエンジンを構築し、顧客の好みに寄り添う体験を作る
マーケティング施策の因果効果を明確に検証する
このような幅広いビジネス課題に対応するため、マーケティングサイエンスに関わるデータサイエンティストは、「統計+AI+ビジネス」のトリプルスキルが求められます。それがこの分野の面白さでもあります。
実践的な事例から見る、マーケティングサイエンス
それでは実際に、企業がマーケティングサイエンスをどのように活用しているのかを、いくつかの事例を示したいと思います。まずは、リスペクトを込めて様々な企業での取り組みを紹介したのちに、レバレジーズでの実践例を示します。
1. サイバーエージェント:ユーザー行動のバイアス補正による予測精度向上
サイバーエージェントでは、ゲームアプリのユーザーが離脱しないように、リテンションを予測するモデルを構築しています。さらに、「コンバージョンが起こるまでに時間差がある」という現実的な問題に対して、遅れコンバージョンモデルというアプローチを導入。ユーザーの行動を中長期でとらえることで、施策の効果をより正確に分析できるようになっています。
【DX最前線】「追いつけない差」を生み出す、データサイエンスの核心 | CyberAgent Way サイバーエージェント公式オウンドメディア
2. リクルート:求人×求職者のマッチングにTwo-Towerモデル
求人情報の推薦は、ECとは異なり「アイテム数が少なく評価データが貯まりにくい」という特性があります。そのため、通常の協調フィルタリングが通用しづらい領域です。
リクルートでは、深層学習によるTwo-Towerモデルを導入し、求人と求職者の両方の特徴を別々にエンコードしています。テキストなどの非構造化データから意味的な特徴を抽出し、コールドスタート問題を克服しています。検索の高速化には近似最近傍探索が用いられ、技術的にも面白い構造となっています。
参考
Recruit Data Blog | Two-Towerモデルと近似最近傍探索による候補生成ロジックの導入
3. Airbnb:宿泊価格を毎日最適化するダイナミックプライシング
Airbnbは、借り手と貸し手のバランスによって価格が日々変動する両面市場です。この需要の変化を捉えるために、価格弾力性を機械学習で推定しています。その結果、宿泊価格のダイナミックな調整を実現しています。
人材紹介業も両面市場ですが、宿泊のように日単位で価格が変わるわけではありません。Airbnbのケースは、両面市場におけるアルゴリズムの活用として非常に洗練されています。
4. Gunosy:インターリービングで高速にA/B検証
Gunosyでは、ニュース記事の推薦アルゴリズムをA/Bテストで評価する際に、より効率的なインターリービング手法を用いているようです。これは、同一ユーザーに異なる推薦パターンを同時に見せることで、迅速かつ信頼性の高い比較を可能にする手法です。
参考
A/Bテストよりすごい?はじめてのインターリービング - Gunosyデータ分析ブログ
5. ZOZOTOWN:多腕バンディットでアイテム推薦を強化
ZOZOTOWNでは、アイテム推薦に多腕バンディットアルゴリズムを活用。ユーザーのリアクションを元に報酬を最適化するというこの手法は、囲碁や将棋のAIにも応用されている強化学習に近い考え方で、ファッションECの現場にも徐々に広がりつつあります。
参考
バンディットアルゴリズムを用いた推薦システムの構成について - ZOZO TECH BLOG
ここでは5つのマーケティングサイエンスに関する企業の事例を調べて紹介しましたが、いかがでしょうか。私はどの事例も非常にエキサイティングだと思います。
レバレジーズでのマーケティングサイエンスの事例10選
私はレバレジーズに入社して10年以上が経ちましたので、手がけてきたマーケティングサイエンスの事例は多数ありますが、ここでは10例ほど紹介しようと思います。具体的な実装例は記しませんが、どのような領域でデータサイエンスを使うのかの参考になれば幸いです。
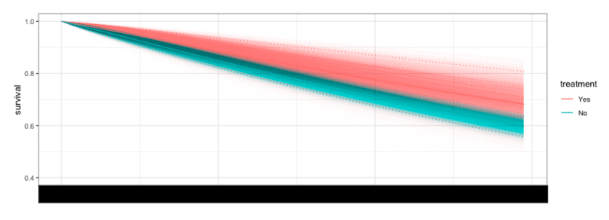
1. 離脱とユーザーの受け取り価格増加率の科学
この分析は5年以上前の分析になりますが、一部の事業部でプライシングの科学をしようとした際に行ったもので、たまたまプライシングを変更した事例を集めて、どのようなプライシングをすれば顧客にとってベネフィットがあるかを生存時間分析を用いて行いました。近年、Stanを用いている人が減ってきた印象がありますが、この当時は社内のあらゆるモデリングをベイズ統計を使って行っていました。
2.サービス登録時点の情報を元にした売上予測
この分析は、7年以上前から取り組んでいるもので、運用型広告においてオフラインのコンバージョンの値をプラットフォーム側に送る際に、人材系のビジネスならではの「コンバージョンしてから売上が発生するまでの長いラグ」の問題を克服するために本来なら数ヶ月かかってもおかしくない売上のデータを登録段階である程度の精度で当てるという取り組みです。使える特徴量が限られているので、精度を向上させることが中々大変だった印象があります。
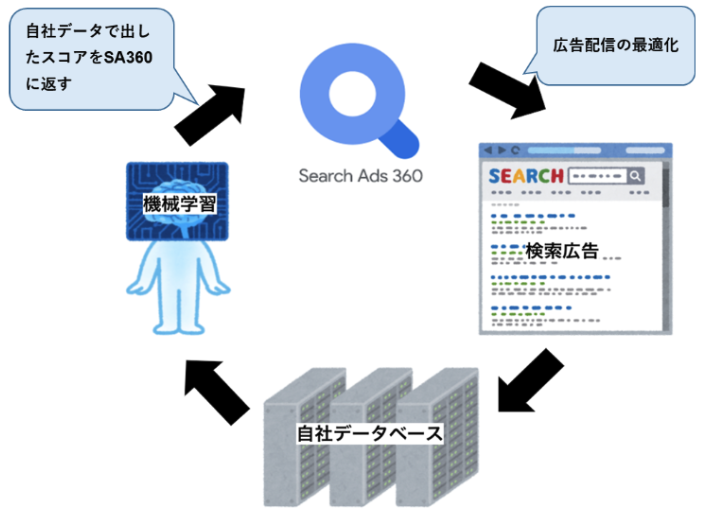
参考
入社半年でやったこと~SA360を用いた運用型広告の最適化 - Leverages データ戦略ブログ
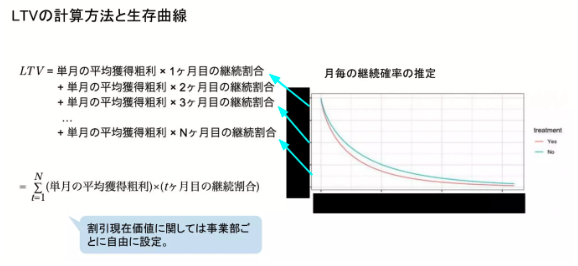
3.生存時間分析を用いたユーザー継続期間の推定
こちらはもう8年以上も前から行っていますが、ベンチャー企業やスタートアップは顧客生涯価値(LTV)と言っても、プロジェクトの回収期間としては無限期間を想定することは現実的ではありません。LTVと言いつつも、1年、2年、3年、4年、5年でどうなるかを知りたいのがビジネスサイドのニーズとなります。そこで、私は月毎の継続確率を扱いやすい生存時間分析を用いてLTVを計算するようにしています。過去のデータが十分にあればバックテストと称して生存時間分析ベースのLTVがどれくらいの誤差で済んでいるのかを確かめるなどもしています。
参考
[丸ノ内アナリティクスバンビーノ#23]データドリブン施策によるサービス品質向上の取り組み | PPT
4.マーケティングミックスモデリングによるオフライン広告などの効果検証
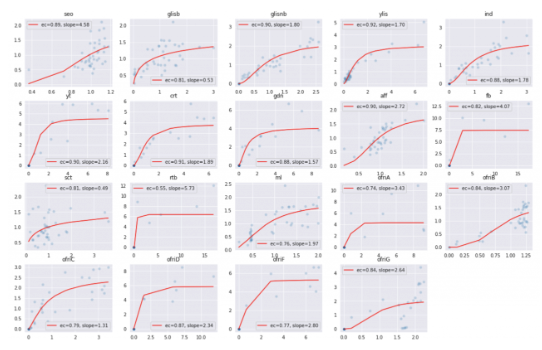
マーケティングでオフライン広告の効果検証と言えば、マーケティングミックスモデリング(MMM)やDIDなどが有名です。今となってはGoogleのMeridian(その以前はLightweight (Bayesian) Marketing Mix Modeling)やMETAのRobynがありますが、4〜5年前はありませんでしたので、MMMの論文をベースにしたコードを参考に毎晩Stanを実行して何時間もかけて収束させていました。可視化に関しても、色々な曲線を描こうとするとハミルトニアンモンテカルロ法(HMC)でのサンプリングを持ってしてもかなりの時間がかかった印象です。今はOSSのライブラリがあるので、とても恵まれています。
以下の図は大昔の自社データを用いてどの経路が広告投資の余地があるのかを可視化したものです。経路によってはサチュレーション(飽和)してそうなものもあります。(ただ、マーケティング担当者の創意工夫次第では乗り越えれたりする世界でもあるのですが。)
5.アトリビューション分析を用いたコンテンツの間接効果推定
これも8年以上前の取り組みですが、当時コンテンツSEOというアプローチに注目が集まっていた時代でして、直接コンバージョンに繋がらないようなコンテンツをかなり作成していました。そこで、マルコフ連鎖モデルを用いたアトリビューション分析により、ページごとの売上に対する貢献度を計算しました。私もデータ戦略室を設立するまではSEOの仕事もしていたので、より価値の高いコンテンツを目指すヒントになるだけでなく、自分たちが作っているコンテンツの間接効果はモチベーションアップにも繋がりました。この分析を通じて、アクセスログをきちんとシステムで残しておくことは重要だと思いました。
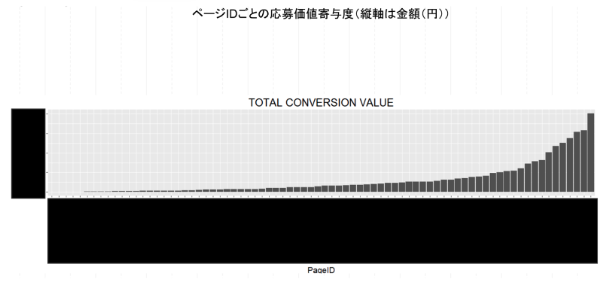
6.アフィリエイトサイトを数万ページクローリングして集めたデータや画像から、CVRの高いサイトの特徴抽出
当時、かなりの数のアフィリエイトサイトと提携しており、どのようなサイトでどのようなサービスに関する説明をされている場合にCVRが違ってくるかを分析しました。サイトの数がかなりあったのでクローリングをするだけでかなりの工数がかかりましたが、自社サービスの説明の仕方や、説明用の画像ごとに差のある傾向を見つけて担当者とより良いアフィリエイト広告出稿の方針を議論することができました。TF-IDF・トピックモデル・画像のマッチングなど色々な技術の合わせ技が生きた事例でした。
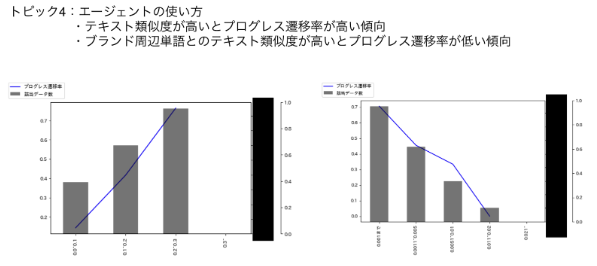
7.音声解析や文字起こしによる営業ノウハウの抽出
最近はLLMの登場により会話からの情報抽出やセグメント分けがかなり捗る時代になってきましたが、5〜6年前は文字起こしの精度も低く、1時間の会話で1ドル以上とかなり高価でした。そのため、限られたデータで何か傾向が見つからないかを試すことが多かったです。 ScipyなどのOSSのライブラリで会話の重なりの分析や周波数解析(F1などの音程)などをある程度できてしまうのでセマンティックな分析以外はそんなに大変ではなかったのですが、形態素解析をして単語ベースで売れっ子の営業担当者とそうでない場合との比較をしても何か全体的な傾向を得ることは難しかったです。LDAなども駆使しましたが中々納得のいくアウトプットにはなりませんでした。
近年はLLMの発達でかなり深い考察が可能になっていますし、OSSのWhisperでの文字起こし精度も必要十分なので音声解析やるなら今が一番いい時期なのかもしれません。
参考
HRビジネスにおけるデータサイエンスの適用 @ BIT VALLEY -INSIDE- Vol.1 | PPT
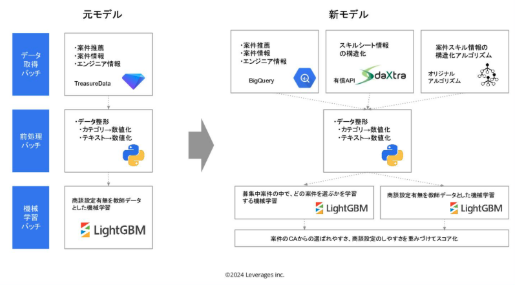
8.求人と人材のマッチングのためのレコメンドアルゴリズム開発
人材系の事業会社でデータ分析を頑張っている会社であればほとんど取り組んでいると思われるのが求人レコメンドアルゴリズムです。多分に漏れなくレバレジーズでも取り組んでいます。RecSysなどの学会の情報や他社のテックブログも参考にしながら、マッチするような求人を見つけるために、どう学習させていくかが重要です。ここ最近はTwo Towerモデルやネガティブサンプリングが主流ですが、私の場合は我流で複数のモデルを使ってアンサンブルさせるなどのモデル保守のコストのかかるようなことをやっていました。どんどん技術は進歩していくので、過去に作った色々なレコメンドアルゴリズムもアップデートしていきたいですね。LLMを用いた会話からの特徴量生成などがレコメンドのマッチ度を高めるのではないかと期待しています。
参考
ももくり3年レコメンドエンジン5年 - Speaker Deck
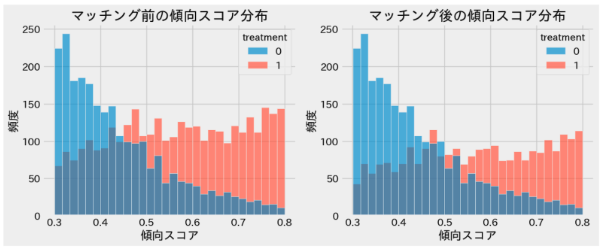
9.営業組織の施策の効果検証のための因果推論(傾向スコアマッチング)
ほとんどのビジネスデータはA/Bテストを実施することが倫理的にもオペレーション的にも難しいことが多いです。そのため、因果推論の傾向スコアマッチングを用いて、バイアスを取り除くことで効果検証を適正に行おうとするケースが多いです。しかしながら、教科書のような美しいマッチングなどにより完璧にバイアスを取り除くことは難しいです。
ビジネスサイドから因果効果を出して欲しいという要望はこないことが多いですが、ヒアリングしていると最終的に多くの方が欲しているものは因果推論なのではないかと思うことがあります。
10.求人情報から顧客の関心のあるタグを生成
求人情報には構造化データと非構造化データの両方が含まれます。前者は年収やポジションのカテゴリデータなどで、後者は業務内容や事業内容などです。私はこれまで構造化データをベースに顧客に送るコンテンツのための分析をしていましたが、LLMを用いて非構造化データから何かタグを生成し、そのタグをベースに顧客に送るコンテンツを分析により決めるという方針に変更しました。その結果、大幅に施策パフォーマンスが改善することとなりました。これは、旧来の構造化データだけでどんなにデータサイエンスで最適化したところで、重要なヒントが隠されていた非構造化データに勝つことはできなかったのではないかという新しい気づきを得られました。特徴量がなければ生成すればいいという新しい時代の潮流を感じています。
以上、レバレジーズのマーケティングサイエンスの事例でした。他にも色々と事例があるので、カジュアル面談などで聞いていただけたら色々とお話できると思います。
自社でアルゴリズムを開発することの意味
さて、事例を15ほど挙げたところで筆を止めてもいいのですが、自社での内製を大事にしているレバレジーズの方針もお伝えできると良いかなと思います。
「このプロジェクト、外部の企業に任せる?社内でやる?」という問いは、あらゆる企業にとっての悩みどころだと思われます。
レバレジーズでは基本的に社内でアルゴリズムを構築しています。Vertex AIやSageMakerのようなMLOps基盤は活用していますが、モデルそのものはOSSを駆使して自作します。これは、「自社の事業に最適化されたアルゴリズムは、内製のほうが良いものができる可能性が高い」と考えているからです。
もちろん、すべての企業が内製すべきとは思いません。外部の専門家の知見を借りることで得られるメリットも大きいです。しかし、社内にデータを活かせる人材がいて、継続的に改善していける体制があるのなら、やはり自前で作れることは競争力につながると考えています。
また、一つのアルゴリズムに工数を大きくかけてしまったとしても、レバレジーズは多くのサービスからなっているため、他のサービスへの横展開をしていけば大きな工数でもペイできることがほとんどです。
生成AIの時代における、データサイエンティストの価値
最近では、ChatGPT、Claude、Geminiなどの生成AIが進化し、「もう人間の仕事はAIに取られるのでは?」という声も聞こえてきます。
データサイエンティストとして自己研鑽しても先があるのだろうかと不安に思うかたも過去にお会いしたこともあります。
実際、Sakana AI社ではAI自身が研究課題を立て、論文を執筆するという「AIサイエンティスト」の事例まで登場しています。
では、データサイエンティストの仕事はどうなるのでしょうか?
私は、統計モデリングの実装や分析に関しては、引き続き人間が担うべきだと考えています。特に、数億円規模の広告投資や施策の意思決定においては、LLMの出力だけに依存するのは現実的ではありません。モデルの前提、データの信頼性、そして結果の解釈。これらをきちんと理解し、意思決定者に説明できるのが、データサイエンティストの役割だと思います。
また、先ほどの15の事例を生成AIが勝手に判断してやってくれるかで言うと、それも違うと思います。どの状況下で何を作るべきかを導くのはやはりデータサイエンティストだと考えています。ただ、3〜5年後はどうなっているかは分かりませんが。
おわりに:マーケティングサイエンスは「飽きない仕事」
以上、マーケティングサイエンスの魅力や会社としての開発方針を共有してきましたが、マーケティングサイエンスの魅力は何か?と聞かれたら、私は「飽きないこと」だと答えます。
プロジェクトごとに必要な知識や手法が全く異なるため、毎回が学びの連続です。加えて、技術だけでなくビジネスの戦略とも密接に関わるため、企業の未来に直結する提案ができます。
統計が好き、機械学習が好き、ビジネスが好き。どんなバックグラウンドを持つ人にとっても、マーケティングサイエンスは非常に面白いフィールドです。
レバレジーズでは、本記事のようにマーケティングサイエンスを駆使して、共に事業をドライブしてくれるかたを積極的に募集しています。
「どうやったら売れるのか?」を、数字とロジックで明らかにする探索の道を一緒に歩みませんか?
求人情報のリンク
データサイエンティスト | レバレジーズ株式会社