はじめに
レバレジーズのデータ戦略室で室長をしている阪上です。
これまでレバレジーズの運営する人材紹介系サービスの事業部内で、業務効率化のためにレコメンドエンジンを開発することが多かったので、つまずいたいくつかの壁について記します。
論文などに裏付けされた書籍に書かれているような観点もあれば、知行合一というか、アルゴリズム開発をやってみて初めて気づける観点もあると思いますので、少しでも参考になれば嬉しいです。
レコメンドエンジンの目的
事業会社としてお客様に求人情報などを提案することが行われていますが、一人の人間が覚えることができる求人情報の数は限られています。
また、求人情報の検索をするにも非構造化データでもある求人情報から目当てのものを見つけるのに時間がかかります。
お客様に合った条件の求人を見つけるのはサービス提供としてマストですが、そのために時間をいたずらにかけることは賢明ではありません。
そこで、今後求人情報がどんどんと増加したとしても簡単にお客様に合った求人を見つけることができる仕組みが重要で、それを実現できるのがレコメンドエンジンだと考えています。
レコメンドエンジンの使い所
AmazonなどのECサイトでは人間を介することなく自動でレコメンドされるのが普通ですが、サービス業の中でレコメンドを使うとなると、人間を介することになります。
そのため、「人間が探した求人」と「レコメンド結果の中から人間が選んだ求人」が混在するハイブリッドなスタイルでの運用になると思います。
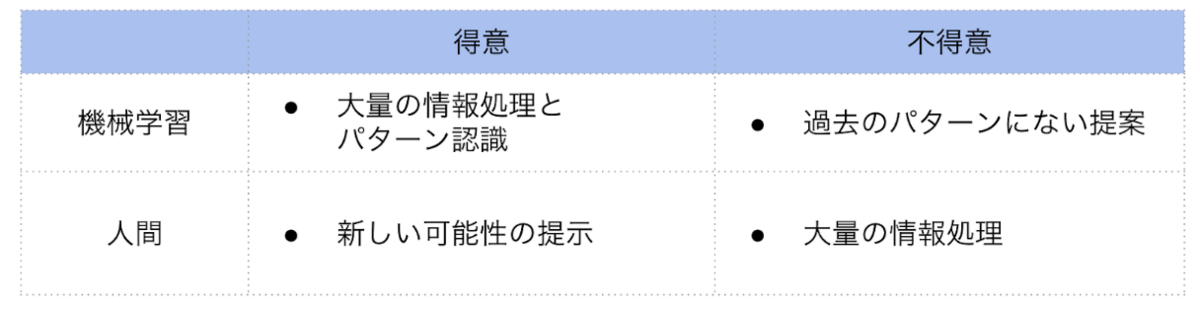
レコメンドエンジンは過去の膨大なデータで機械学習を行いますが、人間のクリエイティブな提案に必ず勝ると言うことはできません。
膨大な求人数の情報処理という人間の限界をレコメンドが補い、人間の想像的な提案がレコメンドエンジンの柔軟性のなさを補うという相互補完関係をイメージして運用しています。
レコメンドアルゴリズムを作るに際しての壁
コールドスタート問題
私の経験の範囲ではありますが、求人情報といった類のものは一つの求人が何度も求職者とマッチすることはなく、マッチすれば求人情報は閉じられることが多く、コールドスタート問題に直面します。
そのため、協調フィルタリングをするにもコールドスタート問題に弱くなさそうなアルゴリズムの選定が求められます。
そういった背景から特徴量のメンテナンスなど運用コストがかかりますが、モデルベースの協調フィルタリングを扱うことが多いです。
偏ったデータでの機械学習が求められる
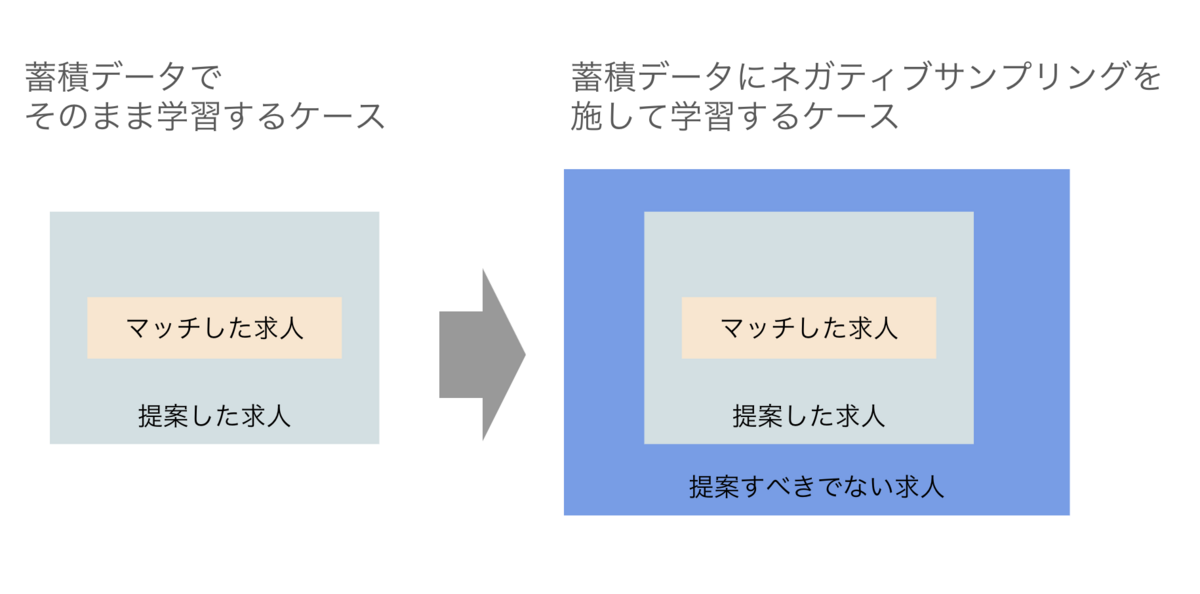
ゼロから機械学習をするとなると、過去の蓄積データを用いて正例と負例を用意します。そして学習用データと推論時のデータに大きな違いがないかを考えます。
そこで、蓄積データには「お客様にご提案しても大丈夫なデータしかないこと」に、推論時には「数多ある求人情報(提案してもいいものや悪いものが混在している!)に対してモデルで予測をしなければならないこと」に気が付きます。
単純に蓄積データだけで機械学習したモデルが意味するものは、「提案できる求人が入力されたらマッチしやすいものを返しますよ」となります。これは推論時の状況とギャップがあると言わざるを得ません。
そのような場合は数多ある求人から提案して問題ない求人を選ぶためのモデルの設計が必要になります。アプローチとしてはネガティブサンプリングとして負例の教師データを別途集めることが多いですが、サンプリング次第で結構精度が変わるので頭が悩まされるところではあります。
過去のログが必ずしもいいデータとは限らない
非熟練担当者がいた場合、蓄積データが意味するものが変わってきてしまいます。熟練担当者よりもベストではない求人を提案している可能性があるためです。
その場合、教師データとして含めない方が性能がアップするような場合もあります。全ての人間の残した実績を学習対象にするべきかどうかは常に考える必要があります。
上書きされるデータ
多くのSFAはお客様や求人情報の状況に応じて情報をアップデートします。
それはサービスとして当然のことですが、同時に学習データを作る際は過去のスナップショットデータを用意しなければなりません。上書きされたデータでEDAをするとおかしな傾向が出ることが多いです。
RDBのデータをそのまま分析に使えるわけではなく、その当時の状態を一度復元する手間が必ずかかります。
非構造化データ
求人情報には求めるスキルがフリーテキストで書かれている場合が多いですし、お客様の過去の経験業務や希望する仕事内容もフリーテキストが多いです。
そのため、そのまま分析に使うことはできないので、レコメンドアルゴリズムのためだけに「非構造化データを構造化データにするアルゴリズム」を開発することもあります。
私は一人で3万件のアノテーションをしたことがありますが、十分な性能のアルゴリズムを作れたので、やる気さえあれば一つの特徴量のためだけにモデルを作るのはやってみてもいいかもしれません。
昨今はLLMという選択肢もありますが、お客様のデータを外部に出すのは言語道断なので、ローカルで動く独自モデルを鍛えるのもありです。

ラベルの正しさ
お客様に提案した求人がすごくマッチしていたとしても、別の理由でお客様が辞退されることは当然ありえます。
それは機械学習において「正例のはずの組み合わせが、負例になっている状況」となってしまいますので、性能の低下に繋がります。
そのため、学習用データに関するドメイン知識がある程度ないと、学習するべきでないものを学習してしまうことになります。
何を学習し、何を学習しないかをうまくこなせないとビジネスのログデータでの機械学習はうまくいかないと思います。
顧客と求人の双方の情報に基づく特徴量の作成
例えば、年収は希望の下限を下回るのは嫌だが、上限を超えるのは問題ないという観点があるように、多くの特徴量は顧客と求人情報の相互により決まります。
例えばスキル情報の合致度のメトリクスを考えるにも、どのスキルを重視するかで組み合わせはかなり多くなり、モデルが複雑化することが多いです。
データ数が十分にあれば深層学習系のアプローチでそこをカバーすることも可能ですが、EDAから地道に双方の情報から特徴量を考えることが多いです。
レコメンドシステムを作るに際しての壁
ニアリアルタイムの要求
レコメンドシステムを使いたい時は概ねお客様にすぐに求人を提案したい時が多いです。
それは最新の情報で推論をすることが、つまりニアリアルタイムでの推論が求められていることになります。
バッチ処理前提で仕事を進めていると色々と困ることもあるので、ニアリアルタイムを意識した前処理などの推論パイプラインの設計が求められます。
推論速度
求人情報は膨大なため、あるいは今後ますます増加していくことから、推論速度を意識したアルゴリズムの作成が求められます。
精度を追い求めるあまり、自然言語処理で複雑な前処理をしたり、かなり大きな次元数で特徴量を作ると本番運用の際に苦しむことになります。
レコメンドシステムを普及させる際の壁
オフラインテストでの信頼獲得
これまでレコメンドシステムを使っていない部署にそれらの導入を提案する際、多くのケースで性能の高さが問われます。
お試しでレコメンドシステムを利用することに二の足を踏んでしまう場合は、オフラインテストを徹底的に行って結果を示していくことが多いです。
あくまでも「人間が提案した求人と同じような求人を提案できたか?」という観点で、「人間の提案を超えるようなレベルのものかどうか」はオフラインテストでは確認できませんが、最低限の品質を担保することはできます。
本当はオンラインテストをしたいところですが、初手ではオフラインテストを徹底的に行うのが定石かなと思っています。
既存の業務からの移行コスト
多くの人間は、慣れ親しんだルーティンを変更することに抵抗があります。現状がある意味で最適化された状態だからです。
その最適化されたルーティンに対し、レコメンドシステムを挟み込むのはそんなに簡単ではないです。
どうすれば利用の負担を減らせるのかをレコメンドシステムの利用者と議論しながら進めていきました。
利用者の負担を減らすために、レコメンドシステムとは少し関係ない領域での効率化をすることもあります。
全員が満たされるものではない
先ほども記しましたが、お客様によっては求人を見つける際に、かなり想像的なアプローチが必要な場合もあります。
場合によってはお客様のために企業側に求人(ポジション)自体を生み出してもらう動きもあることでしょう。
レコメンドシステムのカバー範囲はそれほどまでに広くないので、レコメンド利用者にはその限界を知ってもらった上で使ってもらっています。
「使えるシチュエーションでレコメンドを使う」という判断を各人に委ねてはいますが、うまく使い分けている人が多いと思います。
利活用の大義名分
レコメンドシステムを使う以上、使った方が業務が楽になったり、求人を見つけるのが楽になった結果、お客様がより良い求人に出会えてマッチする確率などが高まらなければ意味がありません。
ある程度条件を揃えた上で、定期的にレコメンドを使った場合と使わなかった場合のKPIの比較などをしています。
そういった利活用のための大義名分はとても重要で、人々のレコメンドシステム利用のモチベーションの源泉になります。
まとめ
今回はレコメンドの教科書に載っていないような、実務ベースのやや抽象度高めな観点を記しましたが、実際に業務で色々試すことで情報推薦の難しさを感じることが多いです。
最初にレコメンドなどのプロジェクトに向き合う際、「最新のアルゴリズムを移植してSOTA(State-of-the-Art)実現したぞ」みたいな興奮があるのかなと思っていたこともあるのですが、蓄積データに様々な仮説で立ち向かい、コツコツと積み上げていくものだという認識に変わってきました。
論文で基礎知識を身につけ、実務で徹底的に試行錯誤するということを引き続きやっていこうと思います。