はじめに
こんにちは、レバレジーズの浜田です。
レバレジーズのデータ戦略室で2年間データアナリストを経験したのち、現在は新卒領域のスカウトサービスでPdMをしています。
データアナリスト時代に同サービスでレコメンド機能の実装を担当しており、今回はそのプロジェクトでの学びをみなさんに共有できればと思います。
サービスのグロースにつながるデータ分析をしたいという方は是非読んでいってください!
プロジェクトの背景
新卒領域のスカウトサービスでは企業が学生にスカウトを送信し、学生が承諾することで選考に進みます。皆さんも転職などで利用した経験があり、スカウトサービスには馴染みがある方が多いかもしれません。
当時は企業からのスカウトに対する学生の承諾率が低下していることが問題となっており、企業が学生を検索できる画面で並び順を工夫することで承諾率を改善できないかという依頼に取り組むことになりました。
依頼元が新規事業だったこともあり
- 並び順ロジックの検討からリリースまで3カ月程度しかない
- 就活開始→締めまで通しでデータがそろっている年度がない
という厳しい状況からのスタートでした。
3つの工夫ポイント
今回はプロジェクトの進め方として自分が意識していたこと、工夫したことを3つ共有できればと思います。
① ロジックの完成度を求めすぎない
短納期かつ新規でレコメンドを実装するプロジェクトだったこともあり、 初回から完成度の高いものを作るのではなく、素早く初版をリリースして改善を早く回せる仕組みを作ることを意識していました。 ロジックの精度に気を取られてしまうのが分析者の性ですが、あくまでもいち機能に過ぎないと考えるようにしていました。
② 解釈性の高い機械学習モデルを活用する
決定木ベースのシンプルな機械学習モデルを用いて「どの説明変数が学生の承諾に効いているのか」を検証する分析を行い、決定木の条件の組み合わせをもとにルールベースで表示優先度を定義しました。 これにより、どんな学生がどんな企業に対してどのタイミングで上位表示されるのかについて開発チーム内で認識を揃えやすくなり、実装フェーズでのコミュニケーションが円滑になりました。
③ ビジネス観点、UX観点でのリスクを事前に洗い出し、先回りしておく
「登録したての学生にスカウトが届きにくくなるのではないか」、「検索時に目立つプロフィール項目を入力していない学生が上位に来てしまうのではないか」など、複数の観点でリスクを事業部側とすり合わせておくことで、リリース後の手戻りを可能な限り少なくしました。
リリース後にKPIが改善!
進め方の話はわかったけど、実際効果はどの程度出たのという部分も気になるかと思います。 リリース後1カ月間でベイジアンABテストを行ったところ、リリースによって平均して承諾率が約1.3倍に改善したことがわかりました。
下のグラフはベイジアンABテストの結果で、Aが今回リリースしたおすすめ順での承諾率の事後分布、Bが従来の並び順での承諾率の事後分布となっています。2つの分布が重なっていないことから承諾率が改善したことがはっきりとわかりますね!
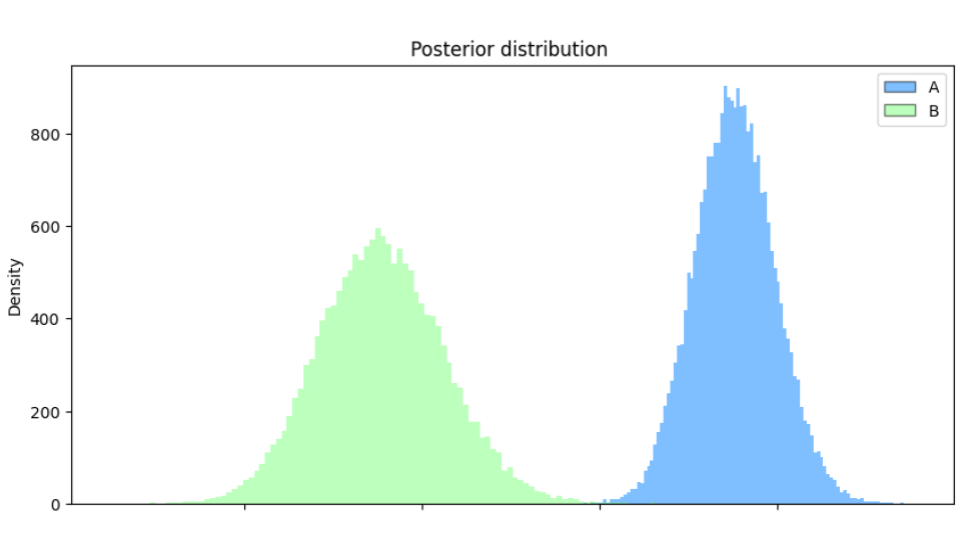
さらに、少なくとも1通スカウトを受け取った学生の割合をリリース前後で比較したところ、約1.5倍に増加していることがわかりました。
承諾率が改善しただけでなくスカウトを受け取る学生の幅も広くなっていることから、サービスのグロースに貢献するデータ活用ができたのではないかなと考えています。
おわりに
いかがだったでしょうか?今回はロジックの詳細というよりもロジックを検討する際の姿勢、工夫したポイントについて書いてみました。
今後の改善として、データ蓄積を進めて就活時期による承諾傾向の違いをアルゴリズムに反映すること、MLOpsの導入による継続的なモデルの更新を行うことを検討しています!
今回でブログの執筆は最後になりますが、別の部署でもひっそりとデータ活用を推進していこうと思います。
読んで下さりありがとうございました!