はじめに
ごきげんよう。
データ戦略室データエンジニアリンググループの楊 (よう) です。
前回は『入社2ヶ月のデータエンジニアの試行錯誤』にて、データ基盤の保守運用・機能改善に携わっている中で試行錯誤したことをご紹介しました。
最近では、データ基盤について少しずつ詳しくなってきて、データ基盤の課題も自分で発見できるようになりました。より効率よく、利便性の高いデータ基盤を構築できるよう、データ基盤の改善に注力しています。
今回はその一環であるBigQueryのビューの定義を自動更新する処理についてご紹介します。
ビューの定義を自動更新する背景
弊社のデータ基盤のユーザーは実テーブルではなくビューにアクセスする運用にしています。その理由は3つあります。
- 全カラムを閲覧できる権限と一部のカラムしか閲覧できない権限をユーザー単位で付け替えるため
- BigQueryのストレージ容量にかかる課金額を1DB分のみに抑えるため
- ユーザビリティを向上させるため
①②の要件だけであれば、Data Catalogのポリシータグを付与することで実現できますし、データ基盤の構築を始めた2020年秋頃はこの形で運用していました。しかしこの運用のままだと、一部のカラムしか閲覧できないユーザーがselect * ~~を使用できませんでした。
データ基盤の活用を全社に広げていくためには、ユーザーにとって利便性の高い基盤が必要です。
そのため、全カラムにアクセスできるビューと一部のカラムを除外したビューを作成し、それらへのアクセス権限をユーザーごとに変更することで、上記の①②③を実現する運用に変更しました。
ただし、データ参照元のDBは、テーブル追加やカラム追加が随時行われていくので、ビューの定義を定期的に更新しなければいけませんでした。
データソースからBigQueryにデータを取り込む処理は毎日夜間に行われており、ビューの参照元となるテーブルは毎日更新されています。
それに対し、ビュー定義の更新は週に1回bqコマンドを使って手動更新していました。データ基盤を構築した当初は、ビュー定義の更新対象となるDBが1つだけだったので手動更新の工数も少なかったのですが、データ基盤の利用が進むにつれてBigQueryへインポートされるDBも増えたため、手動で対応する工数が大きくなってきました。
また、ビュー定義の更新頻度がテーブルと違うことでテーブルやカラムに差分が発生する可能性があり、ユーザーの業務に影響を及ぼす恐れがありました。
したがって、日次でビュー定義を自動更新させる必要があると考えました。
処理の概要
BigQueryで作成するビューは「フルアクセスビュー」と「個人情報が含まれるカラムを除外したビュー」の2種類があります。
データ基盤に蓄積されたデータは、集計してモニタリングしたり機械学習の学習用データとして使ったりする以外に、例えばメール配信や架電のリスト作成等にも使用されています。
データ基盤のユーザーの中には顧客の個人情報を扱う人もいるため、データ基盤にデータをインポートする段階では個人情報をマスクせずにインポートしています。そのため業務で顧客の個人情報が必要な限られたユーザーのみが「フルアクセスビュー」という個人情報が含まれたビューにアクセスできるように制限し、それ以外のユーザーには「個人情報が除外されたビュー」にアクセスするように権限を管理しています。
この2種類のビューを作成する流れが異なるので、ここで簡単に紹介します。
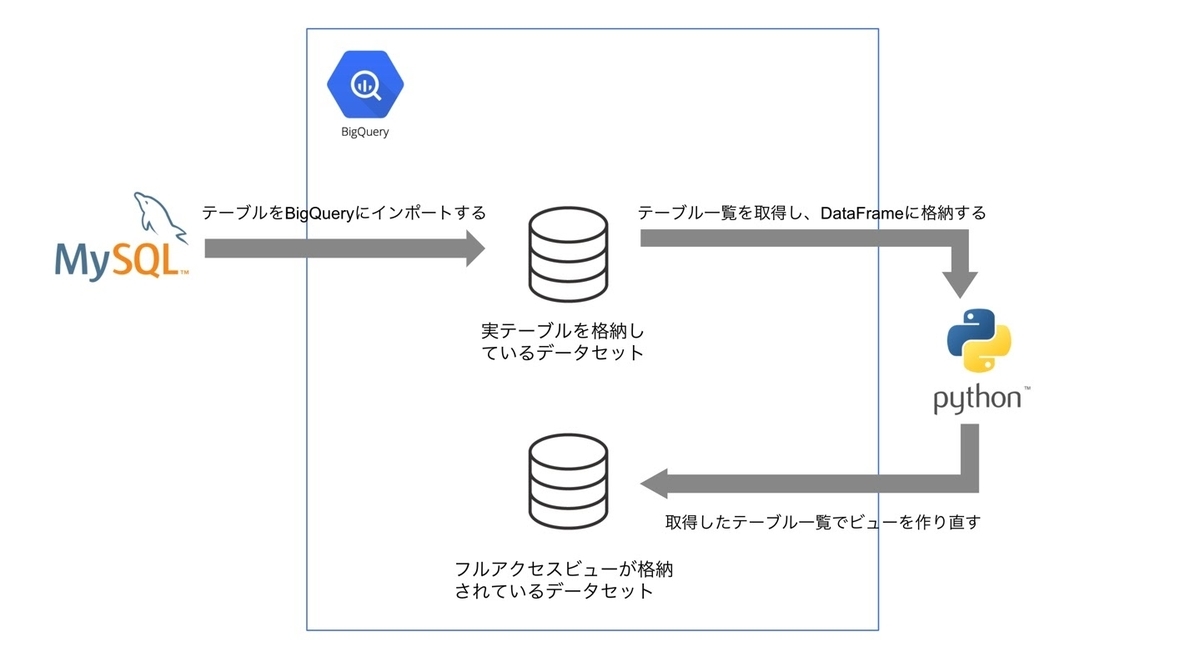
フルアクセスビュー
これは個人情報が除外されず、全てのデータを参照することができるビューを指しています。
簡単な流れは下に図示しているように、テーブルの全カラムをそのままビュー定義に使用しているため、テーブル名があればビュー定義を更新できます。そのため、処理の始めに
select table_name from dataset.INFORMATION_SCHEMA.TABLES
でBigQueryにインポートしたテーブル一覧を取得し、DataFrameに格納しておきます。
そして、BigQuery API クライアント ライブラリを使用し、前日に作成されたビューを削除してから新しく取得されたテーブル情報をもとにビュー定義を作り直し、ビュー参照元のテーブルのデータが更新された後にこの処理を実行するワークフローを組めば完成です。
個人情報を除外するビュー
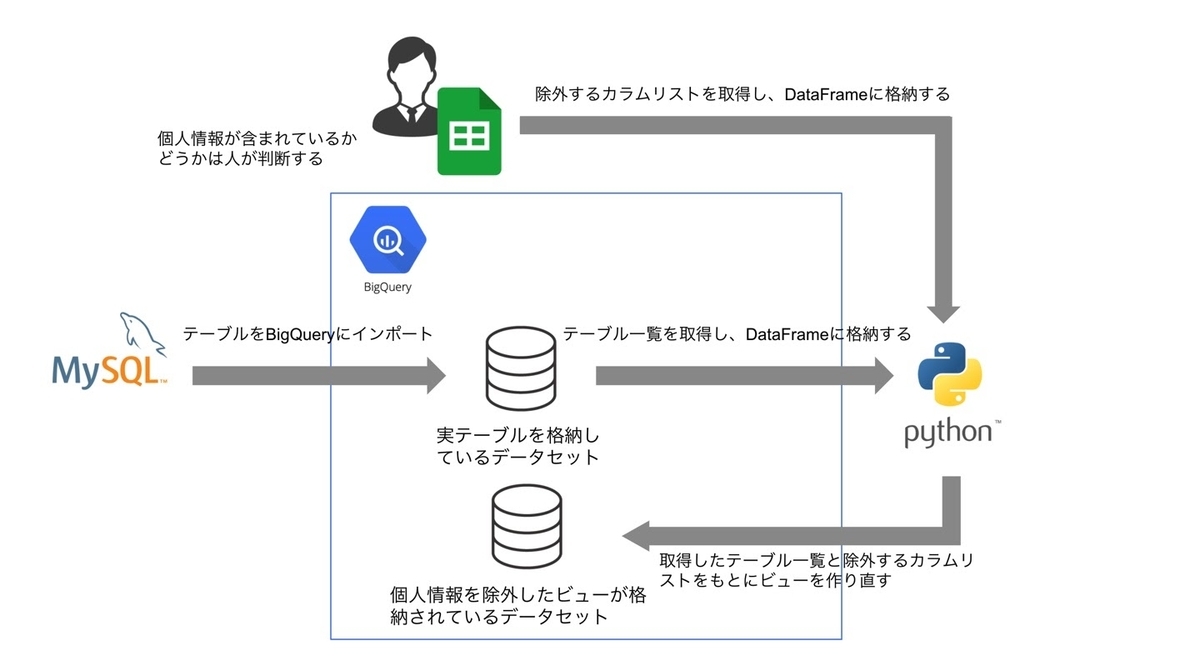
続いては、個人情報を除外するビューについてですが、名前の通り、個人情報を除外した上で作成されたビューのことです。
フルアクセスビューと比べ、個人情報を除外するビューの処理はより複雑で、完全に自動化できていません。
なぜかというと、あるカラムに個人情報が含まれているかどうかは人の目でチェックする必要があるからです。
個人情報が含まれているカラムを選出し、除外カラムリストに入れるのは人の手で実施するしかないのですが、それ以降の工程は自動化することができます。
処理としては、まず、Googleスプレッドシート(Googleスプレッドシートを使用する理由は後述)に格納されている対象DBの除外カラム一覧(個人情報を含むカラム一覧)を取得します。
そして、BigQueryのデータセットから更新対象のテーブル一覧を取得しループを回すのはフルアクセスビューとほぼ同じですが、「個人情報を除外するビュー」は一部のカラムを除外するため、除外すべきカラムが含まれているテーブルはselect * except ( 除外カラムのリスト ) from table_nameでビューを作成し、除外すべきカラムが含まれていないテーブルはselect * from table_nameで全カラムを取得するビューを作成します。
失敗したところと解決方法
処理の流れを見て、それほど難しくないと思う方もいると思います。実装前は私も同じ考えを持っていましたが、油断していたらミスをしてしまいました。
失敗其の一:承認済みビューの追加忘れによりユーザーがデータを取得できない事象が発生
BigQueryの公式ドキュメントには、「データセットに表示アクセス権を設定する場合、BigQuery では承認済みのビューを作成します。承認済みビューを使用すると、元のテーブルへのアクセス権がないユーザーでも、クエリの結果を特定のユーザーやグループと共有できます」と記載されています。現在は、ユーザーにはビューだけが含まれるデータセットへのアクセス権限を付与しており、実データが入っているデータセットに承認済みビューを追加することで、実データが入っているデータセットには権限を与えないまま、ビュー経由でのデータ取得を実現しています。
しかし、最初は承認済みビューに対する理解が浅すぎたため、ビューだけが含まれるデータセットで設定するアクセス権限のようなものだと思い込んでいました。そのため、ビューだけが含まれているデータセットではすでに共有データセットの権限設定が完了しているため、再度設定する必要はないと勘違いしていまいました。そのまま承認済みビューを追加せずにビューの再作成を行ったところ、もともとアクセス可能だったユーザー全員が実データが入っているデータセットへのアクセスが拒否され、データを取得できない悲劇になってしまいました。
<解決方法:承認済みビューを作成する処理を入れる>
一般的にアクセス拒否のエラーを発見したときは、権限設定ミスの可能性に行き着きやすいと思います。実際、私も最初は権限まわりを重点的にチェックしていました。
しかし、誰も権限まわりを変更していなかったため、急にユーザーのアクセス権限がなくなるのは不自然ではないかとも思いました。したがって、直近に実装していたビューの自動更新に目を向けました。
手動更新と自動更新の手順をそれぞれ確認してみると、自動更新の処理の中に承認済みビュー追加の処理がないことが発覚しました。そこで、ビューを作り直す処理の後に、承認済みビューを作成する処理を追加したところ、ユーザーが無事にビュー経由でデータにアクセスできるようになりました。
当たり前ですが、実装する前に、勝手な思い込みを抱かずに実装対象を知り尽くすべきだと思いました。いい教訓を得ました。
失敗其の二:2種類のビューを一斉に更新すると承認済みビューが上書きされる
もともとフルアクセスビューも個人情報除外するビューの承認済みビュー追加の処理では以下のように書いていました:
access_entries = db_dataset.access_entries access_entries.append(bigquery.AccessEntry(None, 'view', view.reference.to_api_repr())) db_dataset.access_entries = access_entries db_dataset = client.update_dataset(db_dataset, ['access_entries'])
フルアクセスビューを更新してから個人情報を除外するビューを更新すると、追加されたアクセスビューの承認済みビューが個人情報を除外するビューの承認済みビューに上書きされてしまいます。
<解決方法:フルアクセスビューの承認済みビューを追加する処理の後ろに、個人情報を除外するビューの承認済みビューを追加する処理を実装する>
インターネットで解決方法を検索しましたが、同様の問題に対する質問や解決方法を紹介したブログが見当たらず、自分で試行錯誤するしかなかったです。
再びソースコードをジーッと見ていたら、access_entries = db_dataset.access_entriesの処理単体では、フルアクセスビューの承認済みビューが存在している状態ではなく、初期化されて承認済みビューが存在しない状態になることに気が付きました。そのため、そのままデータセットをアップデートすると、個人情報を除外するビューの承認済みビューしか存在しないことになってしまいます。
したがって、以下のように、フルアクセスビューの承認済みビュー一覧を取得し、その後ろに個人情報を除外するビューの承認済みビューを追加する処理をいれなければなりません。
db_dataset = client.get_dataset(db_dataset) access_entries = db_dataset.access_entries access_entries.append(bigquery.AccessEntry(None, 'view', view.reference.to_api_repr())) db_dataset.access_entries = access_entries db_dataset = client.update_dataset(db_dataset, ['access_entries'])
既存の承認済みビュー一覧を取得するdb_dataset = client.get_dataset(db_dataset)の1行のみ追加したのですが、自分で肝心な一歩を導き出せるのが気持ちよかったです。
そのほか工夫したところ
今回の自動化の目的は作業の効率化になります。運用のしやすさを考慮した上で、人の作業を最小限にするように設計しました。
除外するカラム一覧の格納先はGoogleスプレッドシートを選定しました。格納先はCSVファイルやテキストファイルなど、選択肢は非常に多く、どれもDataFrameと連携しやすいですが、最終的にGoogleスプレッドシートにした理由は以下2点あります。
- 職種に関係なくデータ管理の利便性が高い。エンジニア以外も除外するカラムの選定を行う可能性があることや追加した除外カラムは翌日の更新で反映させたいことを考慮すると、GithubでCSVファイルやテキストファイルを管理するより、アクセス制限をかけたGoogleスプレッドシートのほうが除外するカラムの更新において利便性が高いと考えました。
- DataFrameと連携しやすい。PythonにはスプレッドシートとDataFrameを連携するライブラリがあるため、それを使うと数行で欲しいデータをDataFrameに入れられます。
最後に
今回はビューの自動更新のみをご紹介しました。現在は、データソースからテーブルとカラム一覧を取得しETL処理に使用する設定ファイルを自動生成する機能や、ユーザーがアクセスするビューのカラムコメントを自動で更新する機能着々と実装しています。 データ基盤は作って終わりではなく、日々改善しながら良くしていくものだと私は思っているので、これからもより効率よく、利便性の高いデータ基盤を作っていけるように努力します。