はじめに
データ戦略室データエンジニアリンググループの江口です。
Google BigQueryに蓄積しているデータをAmazon QuickSightで利用しようとする場合、クラウドベンダーを跨いだデータ連携が必要となります。Amazon Web Services ブログではこのようなユースケースに、AWS Glueカスタムコネクタを用いたデータ連携が紹介されています。一方で、Google BigQueryから変換や加工が伴わずにデータを出力する場合は、Google Cloud Storageを経由したよりシンプルな実装をすることができます。
この記事ではGoogle BigQueryのデータを、Google Cloud StorageとAmazon S3を経由してQuickSightへインポートする方法を、Pythonのサンプルコードを交えてご紹介します。
処理の概要
Google BigQueryから出力されたデータは、はじめにGoogle Cloud Storageに保存されます。次に、Google Cloud Storageに保存されたオブジェクトをAmazon S3にコピーします。最後に、Amazon S3のオブジェクトをAmazon QuickSightからインポートします。
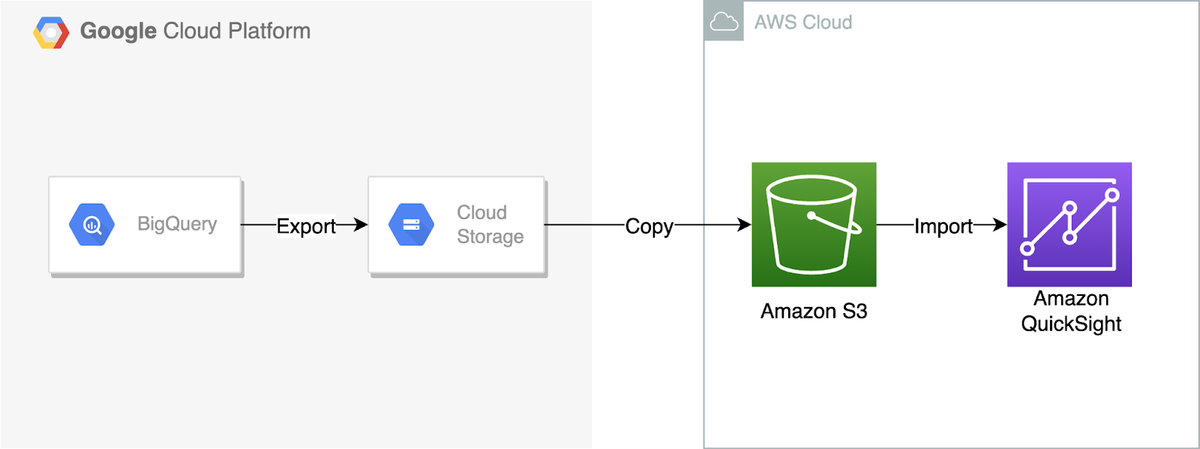
Google BigQueryのデータをGoogle Cloud Storageに出力
BigQuery APIのPythonクライアントを使用して、Google BigQueryのデータをgzip圧縮したCSVとしてGoogle Cloud Storageに出力します。今回は、最終的にAmazon S3を経由してAmazon QuickSightにインポートしますが、そこでサポートされている形式はCSVとなります。そのため、ここではGoogle BigQueryのデータをgzipで圧縮したCSVとして出力します。
ここからの作業は、事前にジョブの実行ユーザーに適切な権限を付与しておく必要があります。詳細はこちらのGoogle Cloud公式ドキュメントを参照してください。
- Google BigQueryのデータを出力するために、出力先となるGoogle Cloud StorageのバケットとURIを定義します。
- 出力するGoogle BigQueryのプロジェクト名、データセット名とテーブル名を定義します。
- 出力時の圧縮方法を指定します。ここではgzipで圧縮をするので、bigquery.Compression.GZIPと指定します。
- ここまでに定義したテーブル名、出力先のURI、圧縮方法およびデータセットのロケーションを指定し、APIにリクエストを送信します。
# 出力先のGoogle Cloud StorageのURIを定義
destination_uri = "gs://bucket_name/object_path/table_name.csv.gz"
# 出力するGoogle BigQueryのデータセット情報とテーブルを定義
dataset_ref = bigquery.DatasetReference(PROJECT_ID, dataset_id)
table_ref = dataset_ref.table(table_name)
# 出力時の圧縮方法を定義
job_config = bigquery.job.ExtractJobConfig()
job_config.compression = bigquery.Compression.GZIP
# APIにリクエストを送信
extract_job = bq_client.extract_table(
table_ref,
destination_uri,
location="US",
job_config=job_config,
)
extract_job.result()
Google Cloud StorageのオブジェクトをAmazon S3へコピー
AWS SDK for Python (以下、Boto3)を使用して、Google Cloud StorageのオブジェクトをAmazon S3へコピーします。Google Cloud StorageをBoto3で操作するためには、相互運用アクセスを有効にしておく必要があります。Google Cloud Storageの相互運用アクセスの詳細はこちらを参照してください。Amazon S3をBoto3で操作するためには、事前に権限を付与したIAMユーザーのアクセスキーを取得する必要があります。アクセスキーの詳細はこちらを参照してください。
また、今回は一連の処理をGoogle CloudFunctionsで実行することを想定し、コピーするオブジェクトをバイナリストリームで処理します。バイナリストリームでの処理にはioライブラリのBytesIOを使用します。オブジェクトを一時ファイルとして処理すると、Google CloudFunctionsのメモリを圧迫する恐れがあります。
- Amazon S3とGoogle Cloud Storageのバケット情報を定義します。(Amazon S3にはIAMユーザーのアクセスキーIDとシークレットアクセスキーが、Google Cloud Storageには相互運用アクセスのアクセスキーとシークレットが必要です。)
- コピーするGoogle Cloud Storageオブジェクトのパスを指定します。
- Google Cloud Storageからダウンロードしたオブジェクトを、バイナリストリームを経由して、Amazon S3にアップロードします。
import io
import boto3
# S3バケットの情報を定義
s3 = boto3.resource('s3',
aws_access_key_id=S3_ACCSESS_KEY,
aws_secret_access_key=S3_SECRET_ACCSESS_KEY,
region_name='ap-northeast-1')
s3_bucket = s3.Bucket(S3_BUCKET_NAME)
# GCSバケットの情報を定義
gcs = boto3.resource('s3',
aws_access_key_id=GS_ACCSESS_KEY,
aws_secret_access_key=GS_SECRET_ACCSESS_KEY,
region_name="auto",
endpoint_url="https://storage.googleapis.com",)
gcs_bucket = gcs.Bucket(GS_BUCKET_NAME)
# オブジェクトのパスを定義
object_name = 'object_path/table_name.csv.gz'
# BytesIO経由でGCSからS3にコピー
io_object = io.BytesIO()
gcs_bucket.download_fileobj(object_name, io_object)
io_object.seek(0)
content = io_object.getvalue()
s3_bucket.put_object(Key=object_name, Body=content)
Amazon S3のデータをAmazon QuickSightにインポート
Amazon S3に保存したオブジェクトをAmazon QuickSightのデータソースとしてインポートします。インポートするオブジェクトのパスは"s3://bucket_name/object_path/table_name.csv.gz"とします。
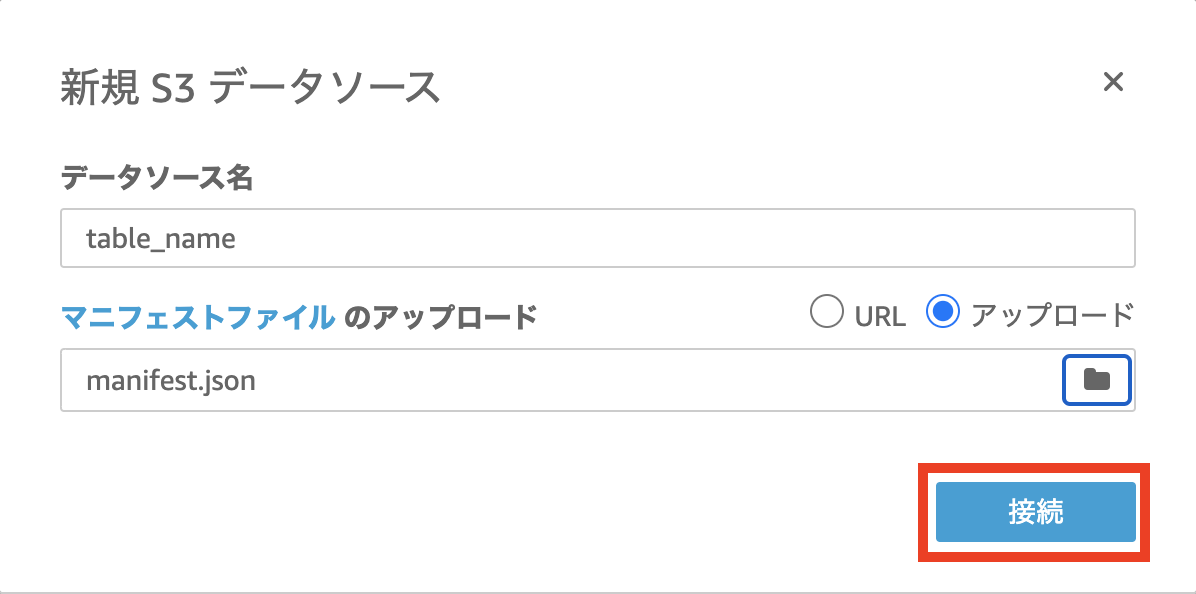
- 以下の例を参考に、データソースのマニフェストファイルを作成します。
- QuickSightの「データセットを作成」->「新しいデータセットの作成」を選択します。
- 任意のデータソース名を入力し、マニフェストファイルを指定します。
- 「接続」を選択します。
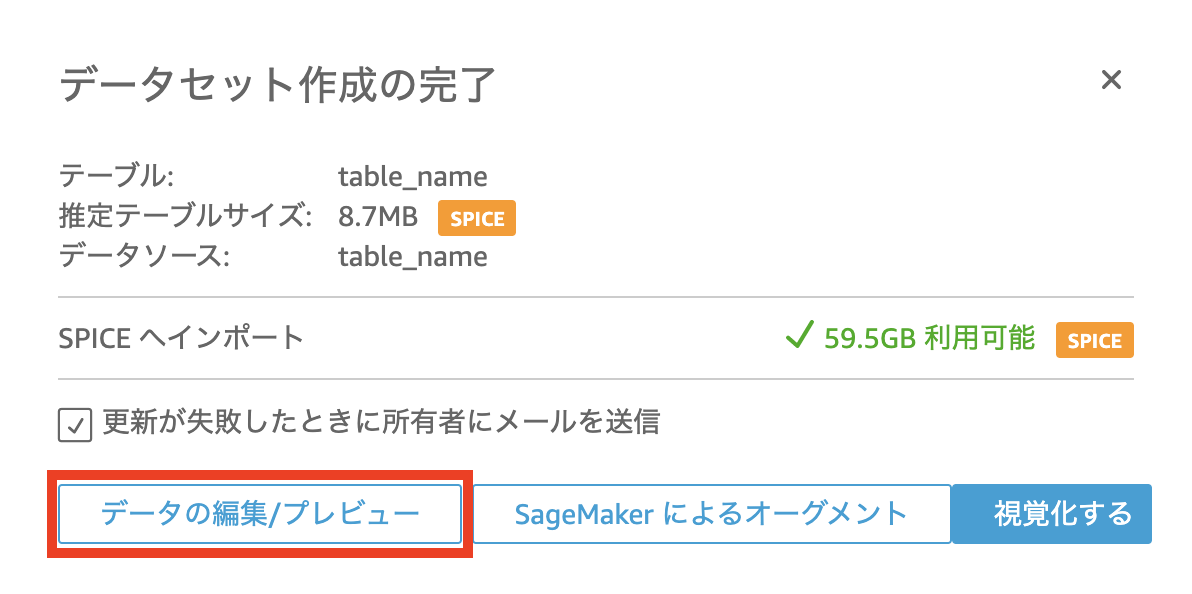
- 「データの編集/プレビュー」を選択します。
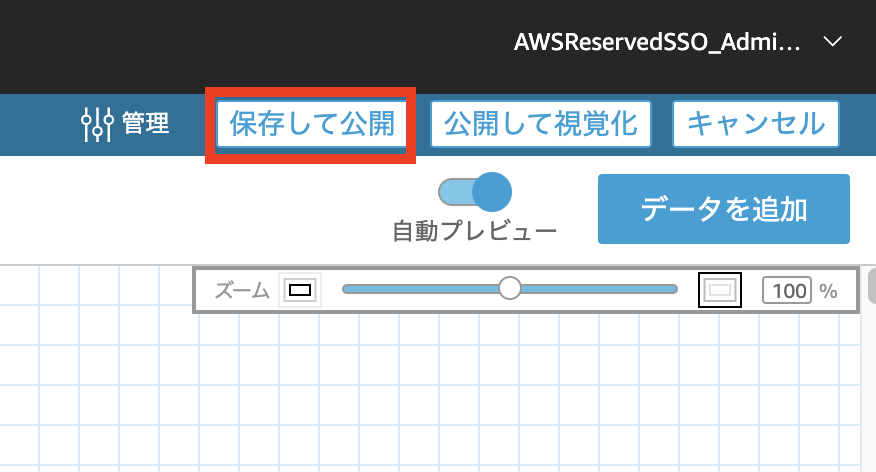
- データセットが正しくインポートされていることを確認し、「保存して公開」を選択します。
以上が全て完了すると、保存したデータセットを用いてダッシュボードの作成を行うことができます。
# manifest.json
{
"fileLocations": [
{"URIPrefixes":
[
"s3://bucket_name/object_path/table_name.csv.gz"
]
}
],
"globalUploadSettings": {
"format": "CSV",
"textqualifier": "\"",
"delimiter": ","
}
}
まとめ
この記事ではGoogle BigQueryから出力したデータをAmazon QuickSightにインポートするまでの一連の流れをご紹介しました。
弊社の実運用においては、上記の処理に加え、オブジェクトのアーカイブなども含めたPythonスクリプトをGoogle CloudFunctionsで実行させています。Amazon QuickSightの更新のスケジュール設定と併せることで、データセットを自動で定期更新するパイプラインを構築することができます。Google BigQueryをデータソースとしたAmazon QuickSightダッシュボードを作成される際には、これらの構成を参考にしていただければ幸いです。
また、今後の課題として、非エンジニアでも簡単に連携対象のテーブルを追加するフローの構築が挙げられます。この記事の方法では新規に連携対象のテーブルを追加する際、マニフェストファイルを作成し、Pythonスクリプトの修正をする必要があります。この作業を簡素化、あるいは単純化することができれば、エンジニアへの都度の作業依頼が不要となり、より効率的な運用が可能となるでしょう。