はじめに
こんにちは!レバレジーズのデータエンジニアグループに所属している内山です。
今回は、社内エンジニアの保有スキル情報を対象に、BigQuery のベクトル検索(vector search)機能を使ったセマンティック検索の PoC を行いました。本記事では、その検証設計・結果をまとめてご紹介します。
この記事の対象読者
- BigQuery でのベクトル検索導入を検討している方
- 社内検索システムをキーワードマッチからセマンティック検索に拡張したい方
- 埋め込みモデルや前処理の選び方で悩んでいる方
この記事を読むとわかること
- BigQuery vector search の検証設計の進め方(モデル比較・前処理比較)
- 多言語埋め込みモデルが日本語混在データに対してどの程度有効か
- 定量評価(distance)だけでは判断を誤る可能性があり、定性評価が決定打になった話
課題:キーワード AND 検索の限界
社内では、エンジニアの保有スキル情報(言語・フレームワーク・ロール経験などのスキルタグ)を BigQuery 上に集約し、Streamlit で構築した検索ツールから AND 検索で絞り込めるようにしていました。
しかし運用していくうちに、いくつかの限界が見えてきました。
- 表記ゆれ問題:「Next.js」「NextJS」「ネクスト」など、同じスキルでも記述パターンがバラバラ
- 類義語問題:「フロントエンド」で検索すると React 経験者が引っかからない
- 粒度のミスマッチ:「機械学習」と検索しても「scikit-learn」「PyTorch」を持つ人にヒットしない
- 意図のズレ:「フロントエンドのモダン技術に強い人」のような自然言語クエリに弱い
これらは「キーワード一致」という仕組み上の制約で、辞書を整備しても追いつかないと判断し、埋め込みベクトルによるセマンティック検索の導入可否を検証することにしました。
今回のPoCのゴール
検証を始めるにあたり、以下の3点をゴールとして設定しました。
- 自然言語クエリで「意図のマッチするエンジニア」を発見できるか検証する
- 「フロントエンドのモダン技術に詳しい人」「クラウドインフラに強い人」のような自然な問いかけで、的確な人材が上位に返ってくるかを見たい
- 既存 AND 検索の拡張として組み込めるかを判断する
- 完全置き換えではなく、構造化検索とハイブリッドで使える形を想定している
PoC の設計
検証では「前処理の粒度」と「埋め込みモデル」の2軸で比較しました。
軸1:前処理の粒度
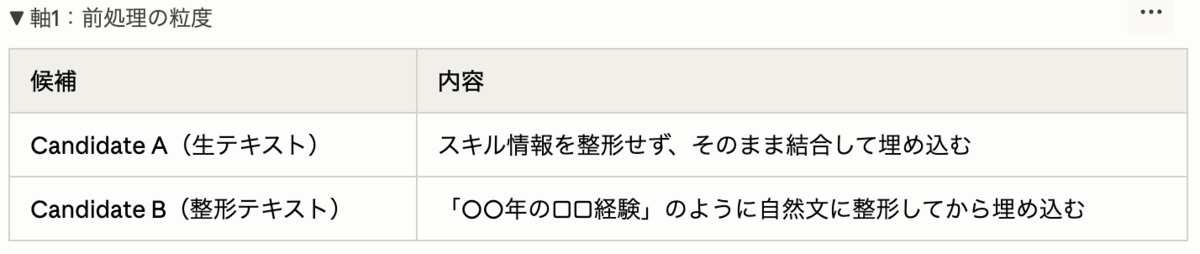
直感的には Candidate B のほうが意味を取りやすそうですが、整形の過程で情報が落ちる可能性もあるため両方比較しました。
軸2:埋め込みモデル

社内のスキルデータは日本語と英語が混在しています。「React を使った Web アプリ開発を3年経験」のような形式です。多言語モデルが効くのか、それとも英語特化モデルでも十分なのかを比較しました。
検証クエリ
実務で実際にありそうな自然言語クエリを6本用意しました。社内営業から実際に要望のあった検索パターンを抜粋しています。
- Java 開発経験者
- React によるフロントエンド開発
- AWS でのクラウドインフラ構築経験
- PM(プロジェクトマネジメント)経験
- Unity でのゲーム開発
- DB 設計経験
評価方法
各クエリに対して、以下の2段階で評価を行いました。
- 定量評価:返ってきた結果の distance(コサイン距離)の数値で組み合わせを比較
- 定性評価:検索結果の上位10件について、Embedding 元の実データ全文を人間が読み、本当にマッチしているかを判定
この 2段階評価が今回のPoCでは非常に重要 になりました。後ほど詳しく書きます。
結果:Candidate A × multilingual が全クエリで期待結果を返した
検証の結果、Candidate A(生テキスト) × text-multilingual-embedding-002 の組み合わせが、用意した6つのクエリすべてで期待した正解エンジニアを上位に含む結果となりました。
4つの組み合わせを比較した傾向は以下の通りです。
| 前処理 | 埋め込みモデル | 結果の傾向 |
|---|---|---|
| Candidate A(生) | multilingual | 全6クエリで期待結果を上位に含む(本命) |
| Candidate A(生) | 英語特化 | PMなど概念語クエリで関係ない職種(アニメーター・作曲家など)が上位に来る |
| Candidate B(整形) | multilingual | 技術名固有のクエリ(Java・DB設計など)で整形時の情報落ちが目立つ |
| Candidate B(整形) | 英語特化 | 上記2つの弱点を両方抱える |
事前の予想に反して、整形した Candidate B より生テキストの Candidate A のほうが精度が高くなったのは大きな発見でした。
※ 本検証は6クエリという小規模なサンプルでの評価のため、精度の絶対値ではなく傾向を捉えることを目的としています。
なお、この結論に至るまでに評価設計上の重要な気づきがありました。distance だけで判断していたら結論が逆転していた可能性があります。詳しくは「評価設計の学び」のセクションで後述します。
評価設計の学び:定量評価だけでは結論を誤る可能性がある
ここが今回のPoCで一番伝えたいポイントです。
少し検証の試行錯誤の経緯を共有しておきます。最初は4クエリのみで distance 比較を行い「Candidate B(整形テキスト)が優位」と一度は結論を出しかけました。しかしレビューフィードバックを受けて定性評価の導入と多言語モデルの追加検証を行ったところ、結論が逆転。さらに Unity・DB 関連クエリを加えて6クエリに拡張し再確認することで、現在の結論に至っています。評価設計の組み立て方次第で結論が大きく変わることを身をもって経験できた、今回のPoCで最大の収穫でした。
もう少し詳しく書きます。実は最初に定量評価(distance の数値比較)だけを実施した段階では、「Candidate B(整形テキスト)が優位」という結論を出しかけていました。distance の数値だけ見れば、Candidate B のほうが小さい値(=意味的により近い)を返していたためです。
しかし、レビューでフィードバックをいただき 「上位10件の実データを人間が読んで本当にマッチしているか確認する」定性評価 を追加で実施したところ、結論が逆転しました。
具体的には、
- Candidate B は distance こそ小さいが、整形プロセスで具体的な技術名・プロジェクト文脈が落ちており、上位に「それっぽいけど少し違う」結果が並ぶ傾向があった
- Candidate A は distance がやや大きくても、上位10件を人間の目で確認すると、より的確な人材が含まれていた
この経験から得た学びは以下の通りです。
- distance はあくまで「ベクトル空間上の近さ」であり、ビジネス文脈での「マッチ度」とは必ずしも一致しない
- 特にセマンティック検索のような新規導入検証では、定量評価と定性評価の両輪で判断する必要がある
- 小規模でも実データを目視確認するプロセスを評価設計に組み込むことで、判断の質が大きく上がる
ベクトル検索を導入する際、distance や類似度スコアといった数値指標は便利な反面、それだけに頼ると判断を誤りやすいということを実感しました。
考察:なぜ生テキストが勝ったのか
1. 整形による情報欠落
「○○年の□□経験」のような自然文に整形する過程で、元データに含まれていた具体的な技術名やプロジェクト文脈が落ちてしまうケースがありました。埋め込みモデルは想像以上にノイズに強く、整形して情報量を減らすより、生のまま渡したほうが良いというのが今回の学びです。
2. multilingual モデルの日本語耐性
text-multilingual-embedding-002 は、日本語のスキル名と英語のフレームワーク名が混在するテキストでも、意味的に近いベクトルにマッピングできていました。「フロントエンド」というクエリで、説明文に "React" や "Vue" としか書かれていないエンジニアもヒットしたのは大きな成果です。
英語特化モデルでは、日本語の概念語(例:「決済」「インフラ」「PM」)が埋め込みベクトル空間でうまく表現されず、検索精度が落ちる傾向が見えました。
BigQuery vector search の使い方(ざっくり)
参考までに、検証で使った主要なクエリの形を載せておきます。
埋め込み生成
SQL
-- リモートモデルの作成
CREATE OR REPLACE MODEL `project.dataset.embedding_model`
REMOTE WITH CONNECTION `project.region.connection_id`
OPTIONS (ENDPOINT = 'text-multilingual-embedding-002');
-- 既存テーブルのテキストカラムを埋め込みベクトルに変換
CREATE OR REPLACE TABLE `project.dataset.engineer_embeddings` AS
SELECT *
FROM AI.GENERATE_EMBEDDING(
MODEL `project.dataset.embedding_model`,
(
SELECT
engineer_id,
raw_text AS content
FROM `project.dataset.engineers`
)
);
ベクトルインデックス作成
SQL CREATE OR REPLACE VECTOR INDEX engineer_embedding_index ON `project.dataset.engineer_embeddings`(embedding) OPTIONS ( index_type = 'IVF', distance_type = 'COSINE' );
検索クエリ
SQL
SELECT
base.engineer_id,
LEFT(base.raw_text, 200) AS content_preview,
distance
FROM VECTOR_SEARCH(
TABLE `project.dataset.engineer_embeddings`, 'embedding',
(
SELECT embedding
FROM AI.GENERATE_EMBEDDING(
MODEL `project.dataset.embedding_model`,
(SELECT 'クラウドインフラに強いエンジニア' AS content)
)
),
top_k => 10,
distance_type => 'COSINE'
);
既存の BigQuery 環境に SQL を流すだけでベクトル検索が組めるのは、体験として非常に良かったです。
本番投入に向けた残課題
PoC は成功しましたが、本番投入に向けては以下の点を継続検証する必要があります。
- 正解データの拡充:今回の6クエリは社内営業からの要望をもとに抜粋したもので、サンプル数が限られています。本番投入時はクエリログをもとに継続的に評価セットを更新する運用を想定しています
- 既存 AND 検索との併用設計:完全置き換えではなく、構造化された絞り込み(経験年数・営業ステータスなど)と組み合わせるハイブリッド検索の設計
- 更新フロー:スキル情報が更新されたときに、どのタイミングで埋め込みを再生成するか
- クエリのチューニング:自然言語クエリ側にもユーザーの書き癖があるため、UI 側でのガイド設計が必要
まとめ
BigQuery の vector search を使った社内エンジニア検索のセマンティック化 PoC で、以下の知見が得られました。
- 多言語埋め込みモデル × 生テキストの組み合わせが、日本語/英語混在のスキルデータに対して期待通りの結果を返した
- 整形は逆効果になることがある。埋め込みモデルはノイズに強いので、まず生のまま入れて様子を見るのが良い
- 定量評価(distance)と定性評価(実データ目視確認)の両輪で判断することが重要。distance だけ見ると判断を誤る可能性がある
- 既存 AND 検索の置き換えではなく拡張として導入するのが現実的
「ベクトル検索を入れたいけど別途インフラを立てるのは大変そう」と感じていた方の参考になれば嬉しいです。
ここまで読んでいただき、ありがとうございました!
参考資料
検証・実装にあたって参考にした記事を紹介します。
Google Cloud 公式ドキュメント
- Introduction to embeddings and vector search
- BigQuery における埋め込みとベクトル検索の基本概念。VECTOR_SEARCH、AI.SEARCH、AI.SIMILARITY の使い分けや autonomous embedding generation の概要を理解するのに役立った。
- Manage vector indexes
- CREATE VECTOR INDEX の具体的な SQL、IVF / TreeAH の違い、pre-filtering vs post-filtering の解説。実装時のリファレンスとして必須
We are hiring!
レバレジーズでは一緒にデータプロダクトを作ってくれる仲間を募集しています。 ご興味を持っていただけた方は、以下からぜひご応募ください。