
データ戦略室で室長兼データサイエンティストをしている阪上です。本日は会社にある非構造化データを宝の山に変えたボトムアップでの取り組みについて紹介したいと思います。最後にはプロンプトのサンプルも付録としてつけておりますので、参考にしていただけると幸いです。
なお、冒頭の画像は、今回作成したツールのイメージキャラクターで「トンでも君」です。私は社内で開発したツールにイメージキャラクターやユニークな名前を付けることをしばしば行います。今回は、宝物を見つける→トリュフは宝である→豚はトリュフを見つける→豚のキャラクターにするという思考回路です。
背景と制約
一昔前まで、お客様の仕事経験に関する匿名の情報を多く保有していましたが、その情報はPDFなどの書類であるため、検索をすることができませんでした。
現場のみなさんも、検索はできないものとして複数の情報を繋ぎ合わせてお客様情報の絞り込みをしておりました。それらは部分一致で引っ掛けるだけなので、中々絞り込めず非常にペインの伴う検索と言えます。
そこで、私たちは書類から構造化データを生み出して検索できるような環境を作ろう、社内の色々な人がアクセスする可能性や特徴量として利用する可能性から個人情報が混入しないような構造化データを作ろうと思い立ちました。
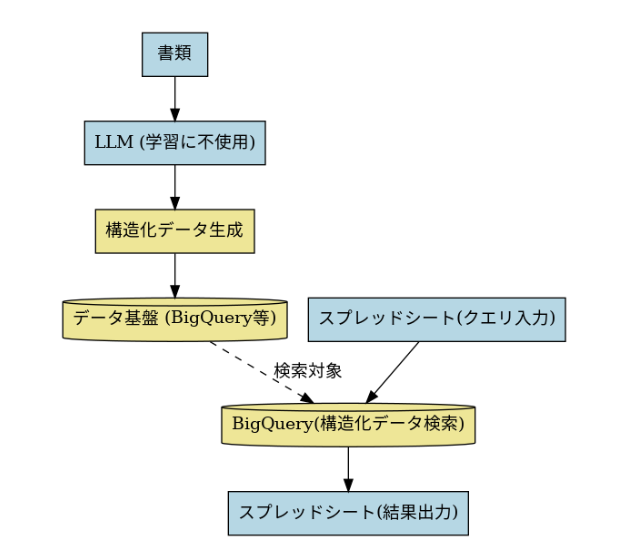
今回扱うPDFは大きく分けて2つの形式があります。エクセルをPDFにしたもの、ワードをPDFにしたものです。ファイルの型に関しても、PDFでそのまま読めるもの、画像としてしか読み込めないものの2つに分かれます。画像の場合は読み込むためにOCRが必要になります。
そのため、構造化をするにも色々なPDFに対してきちんと正しい結果を出力してくれるようなプログラムが必要となります。
処理の概要
処理の概要としては、大きく分けてバッチ処理とリクエストに対して処理するニアリアルタイム処理の2つに分かれます。
まず、バッチ処理に関してはAirflow経由でSageMaker Processing Jobの定期実行を行っていますが、毎日、データベースにアップロードされる書類で、未処理のものを取得しに行きます。そして、学習データに利用されないようなLLMを用いて、構造化のためのプロンプトをAPI経由で実行し、その結果をBigQueryのデータ基盤に蓄積します。なお、SageMakerを使う理由は、一箇所でバッチ処理を管理する環境として便利なのと、RDSにアクセスするためのネットワーク設定がすでにあるためです。Cloud Runなどでも当然できます。
続いて、ニアリアルタイム処理では、ユーザーがアクセスできない環境にGASを置き、そのGASからBigQueryを実行しスプレッドシートにデータを引っ張ってくるなどをしています。できるだけ多くのユーザーに検索をして欲しいので、BigQueryの権限を付与せずとも使える環境にこだわりました。匿名化された仕事経験の情報と、ただのIDしか返されないので、本当に多くの方に利用していただける情報と言えます。具体的には、スプレッドシートで入力した情報を元に、GASでBigQueryのクエリが書かれ、クエリを実行し、データをユーザーが入力したシートに返す流れとなります。なお、スプレッドシートを使うのが主流ではない会社においては、GASは不要でCloud Runにも置き換えられると思います。
プロンプトの苦労話
思えば、部署内でLLMを本格的に使った初めてのプロジェクトだったと思うのですが、すんなりとうまくいくことはなかったと言えます。
最終的なプロンプトは付録にありますが、かなり苦労したかけがえのないプロンプトなので、断片的に記述を消去しています。ニュアンスだけ伝わると良いです。
まず最初に苦しんだのは、LLMに悪用を疑われてエラーが起きるところでした。きちんと「処理結果をどう利用するのかの理由」を記載することでそのようなエラーが起きることはなくなりました。これに関しては、個人情報がない書類にも関わらず起きたので驚きました。
次に、書類の構造化なのでJSON形式でデータを出力するようなLLM側の設定をしますが、ここでも一筋縄では行きません。JSON風のデータの先頭の要素が途切れていたり、破損した形でJSON風のデータが返ってくるなどが高頻度で発生しました。
仕様上、JSON出力が約束されたはずなのですが、壊れたJSONが頻発するのでとても悲しい気持ちになりました。
そこで、出力形式のJSONのサンプルを丁寧に2~3セットほど記してプロンプトにしのばせたり、仮にJSONが破損しても前処理を施すことでPandasデータフレームとして読み込めるようにしたり、LLMの適用部分でのリトライ処理を施すなどして、最終的に処理が成功するようになりました。失敗のパターンはかなりの種類あったのですが、どうにかカバーしました。
今となってみれば、Pydanticのアプローチを取ればJSON化でそんなに苦労しなかった可能性がありますが、それでもたまにエラーは起きるので絶対にエラーが起きない仕組みは難しいと思います。
# 【JSON前処理関数】 import re def preprocess_json(response_text): # まず、Pythonのリストとして手動でパースできるようにする # 手動で中の各キーを抽出して直す # 1. {} の中だけ取り出す obj_text = re.search(r'\{.*\}', response_text, flags=re.DOTALL).group(0) # 2. 各フィールドに分割 fields = re.findall(r'"(.*?)":\s*(?:"(.*?)"|"(.*?)"|"(.*?)"|"(.*?)"|"(.*?)"|"(.*?)"|"(.*?)"|"(.*?)"|"(.*?)")', obj_text) # 3. フィールドをkey-valueで作る data_dict = {} for field in fields: key = field[0] # 値はどれかに入っている value = next(v for v in field[1:] if v != "") data_dict[key] = value # 4. "skills"だけ特別処理する # →もとの壊れた部分を取り出して安全にエスケープする raw_skills= re.search(r'"skills":\s*"(.*)', obj_text, flags=re.DOTALL).group(1) # 5. 最後の"}"を除去して本文だけ取る raw_skills = raw_skills.rsplit('"}', 1)[0] # 6. 壊れた " をすべてエスケープ fixed_skills = raw_skills.replace('"', r'\"') # 7. 辞書に反映 data_dict["skills"] = fixed_skills # 8. 最終的なリストに final_data = [data_dict] # 9. 出力 return json.dumps(final_data, ensure_ascii=False, indent=2)
# 【LLM実行のリトライ関数(補助関数の詳細は省略)】 import time def retry_request(contents, n_retry=1, wait_time=1, model=model_fast): """ Retry LLM API call when it fails. - n_retry: number of retry attempts - wait_time: initial wait time (seconds), doubled each retry Returns: (response, DataFrame) """ response, each_df = None, None for attempt in range(1, n_retry + 1): try: # APIリクエスト response = get_content(contents, model) # JSON整形 fixed_json_data = replace_invalid_escape_sequences(response.text) fixed_json_data = fixed_json_data.replace(",}", "}") fixed_json_data = fixed_json_data.replace("]\n", "]") # JSON→DataFrame try: each_df = from_json_to_df(fixed_json_data) break # 成功したら終了 except Exception: # fallback: JSON前処理を挟む each_df = from_json_to_df(preprocess_json(fixed_json_data)) except Exception as e: print(f"[Attempt {attempt}] Error: {e}") # サンプル用途 if attempt == n_retry: raise time.sleep(wait_time * (2 ** (attempt - 1))) return response, each_df
# 【プロンプトを実行して構造化データのデータフレームを作る関数】 def prompt_do_and_result_append(contents, df, model): ''' プロンプトを実行して構造化結果をデータフレームに追加する関数 ''' response, each_df = retry_request(contents, n_retry=5, wait_time=1, model=model) df = pd.concat([df, each_df], axis=0) return df
なお、パラメータに関しては創造性を求めていないのでtemperatureは0にしています。
ハルシネーション周りですが、令和や昭和などの日本ならではの年号を元に経験した仕事経験の期間を計算してもらったら全く違ったものが返ってきたり、西暦で書かれていたとしても、日付と日付の差分の計算などがかなり不正確であることもありました。そこで、LLMに日付の計算をさせるのはあまり現実的ではないだろうし、日本の年号に強くなる印象も持てなかったので、あくまでもLLMでは期間だけ抽出して、年号の西暦への変換や日付の差分の計算はPandasで行うなど割り切ることとしました。
ハルシネーション以外でも、PDFのOCRの精度の問題や、OCR結果に対するLLMの解釈の仕方でおかしな構造化データが生み出されることもありました。問題があればプロンプトに反映していくという地味な作業の繰り返しを何ヶ月も行いました。
評価方法
当初、LLM自体に構造化したデータについて精査させるというアイデアもありましたが、自分の目を信じたかったので、1000件ほど真心を込めてアノテーションをし、正解データを作りました。余談ですが、私自身は大規模なアノテーションをした経験があり、1000件はそこまで大変には感じませんでした。
LLMで生成した構造化データに対して、アノテーションしたデータにおいて95%の精度を追求し、それを満たすまでプロンプトの改良を繰り返しました。別の仕事もしてましたが、紆余曲折を経て3ヶ月が経過していたと記憶しています。最終的には精度は95%を超えました。残りの5%に関しては、かなり特殊な記述のされ方のPDFだったので、100%を目指すのは当初の想定通り諦めました。
匿名化やセキュリティのこだわり
構造化した仕事経験の情報は、社内のできるだけ多くのユーザーに不便なく検索してもらいたいと思っており、抽象化した仕事経験だけを抽出できる仕組みづくりにこだわりました。
職場の情報や仕事内容は匿名ではありますが、フリーテキストというリスクを考慮すると無差別にアクセスさせるべきものではありません。そのため、抽象化された仕事経験のみで絞り込み、それらが表示されるようなインターフェースをスプレッドシートで用意しました。このような配慮の結果、これまでBigQueryの権限を仰々しく付与したりして一部の人しか使えなかった検索システムをより多くのユーザーに使ってもらえるようになりました。
さらなる前処理
今回のプロンプトでは何年から何年、何をやったかは抽出できますが、何年何ヶ月どの仕事や職種をやったのかは別途計算が必要です。仕事内容の期間が重なる時は、仕事経験情報のオーバーラップ処理なども必要になります(以下にサンプルコードを載せます)。また、仕事経験情報に表現の揺らぎがある場合は名寄せを行う必要もあります。
def remove_overlap(df): ''' 重なった経歴の期間(オーバーラップしたもの)を修正するための関数です ''' # 各期間の始まりと終わりを定義します df['start'] = df['year_month_fixed'] df['end'] = df['year_month_fixed'] + pd.to_timedelta(df['month_gap']*30, unit='D') # latest_endが仕事経験情報の生成日を超えないようにする df['end'] = np.where(df['end'] > df["job_created_at"], df["job_created_at"], df['end']) # 初期値をセットします total_months = 0 latest_end = df.iloc[0]['start'] # 期間を追跡し、重なりをチェックします for index, row in df.iterrows(): if row['start'] >= latest_end: total_months += row['month_gap'] else: overlap = (latest_end - row['start'])/pd.Timedelta(30, 'D') total_months += max(0, row['month_gap'] - overlap) latest_end = max(latest_end, row['end']) return total_months
成果
成果は直接と間接の2つの側面で語れますが、まず直接の成果としてはお客様の情報のプールから今回用意した検索ツールにより直近N年以内の経験した仕事内容からお客様を探すことで、マッチングが成立しています。お客様を探すのに伴う時間としては社内試算で40%ほどは削減できています。具体的な利用件数の数値は載せませんが、多くのユーザーが利便性を感じて毎日使ってくれています。

間接の成果ですが、構造化した仕事内容のデータは匿名性が高いとのこともあり、様々な分析における特徴量として使えたり、Sentence Transformerでの埋め込み表現を用いた顧客の仕事内容間の類似度の計算も可能です。また、因果推論を行う際の顧客のマッチングの際にこのような仕事内容でのマッチングも選択肢に入ってくるので、分析の幅も広がります。
学び
データサイエンティストとして、きっと便利だろうという信念のもとでLLMと格闘し、ツールを作ったところ、かなりのビジネス的な成果を生み出すことができました。トップダウンで依頼が来る仕事だけでなく、ボトムアップで成果を出せるのもこのレバレジーズという会社の魅力なのだろうと思います。
また、満足のいく水準までプロンプトを育てることに苦労したり、アノテーションデータを頑張って作ったり、予想以上に泥臭く忍耐力が求められるのが生成AIの絡んだプロジェクトなのではないかとも思いました。完璧を求めなければ気は楽なのでしょうが、精度95%を達成するための七転八倒な体験は、自分の部下たちに味わってもらうかどうか葛藤するところです。「完璧は高級品」というのは組織としての大きな学びと言えます。
付録
# 【プロンプト例】 prompt_first_direction = """ この処理の目的は、hogehoge(ここはダミー名)の情報を構造化してデータベースに格納することにあります。 添付したPDFの文章を読み込んで、期間ごとに分割してjsonで返して欲しいです。jsonは長くなっても削らずに返してください。 Pandasのread_json形式で['startDate', 'endDate', 'description', 'jobs']という形で読み取れるようにしてください。 ただし要素名は以下のフォーマットでお願いします。 添付したPDFは主に、piyopiyo(ここはダミー名)などのhogehoge(ここはダミー名)です。 フォーマットによっては期間が取得しにくいと思いますが、出来るだけ正確に期間を取得して欲しいです。 フォーマットによっては、同じ経験を複数回記載していることがありますが、それは同じ経験として扱ってください。 以下のjsonのフォーマットで返してください。階層を増やさないでください。 startDate:開始日 endDate:終了日 description:詳細 jobss: 仕事内容のリスト """ prompt_second_direction = """ jsonのサンプルを念の為、ここに共有しておきます '[ { "startDate": "2023-03", "endDate": "2024-03", "description": “ケバブのトッピングや仕込み、販売の経験、フードトラックの運転", "jobs": [ "調理", "自動車運転", "接客", "仕込み", ] }, { "startDate": "2021-03", "endDate": "2022-03", "description": "毎分10本のバナナを処理、クリームを均等に塗ることができる、石窯オーブンの取り扱い", "jobs": [ "調理", "石窯オーブン", ] } ]' """
レバレジーズでは、本記事のようにLLMを駆使したり、以前の記事にあるようにレコメンドエンジン開発を進めてくださる方を積極的に募集しています。
社内に蓄積されたデータを共に宝に変えてみませんか?
求人情報のリンク
データサイエンティスト | レバレジーズ株式会社