はじめに
こんにちは。
レバレジーズデータ戦略室、データアーキテクトの浅見です。
データ分析基盤としてBigQueryを活用している企業は多いと思いますが、それに伴う「権限管理」はどのように行なっているでしょうか。
レバレジーズでは、データ戦略室以外の組織でも BigQueryを活用したデータ分析を各自が行なっています。
そのためデータ戦略室では、現場の社員に対して BigQueryのデータ閲覧権限を付与する必要がありますが、この「BigQueryの権限付与オペレーション」は、データガバナンスと業務効率の観点から課題となっていました。
データ分析基盤を構築するだけでなく、データ利用における課題を解消し、ガバナンスと利便性を両立させることも、データアーキテクトの重要なミッションです。
そこで今回、Pythonだけで動的なWeb アプリを構築できるStreamlitを活用し、BigQueryの権限付与フローを自動化・一元管理するアプリを自作することにしました。
なお、業務でWebアプリを構築するのは今回がはじめてで、手探りしながらの開発となりました。
そのため、本記事では完成形だけでなく、設計段階で意識したポイントや悩んだ点も含めて整理しています。
本記事では、このアプリ開発プロジェクトにおける「要件定義」と「設計」のプロセスを、課題解決の視点からご紹介します。
Streamlitの選定理由
社内向けWeb アプリの要件定義と設計のプロセスについて触れる前に、そもそもなぜ今回Streamlitを選んだのかについて言及しておきます。
「誰がどのように継続的に使えるか」を重視して技術選定を行った結果、以下の理由でStreamlitが適切だと判断しました。
Pythonだけで完結
- Streamlit は Python だけで UI からロジックまでを記述できるため、新たな技術スタックを増やすことなく、既存スキルの延長で開発できる点が大きな魅力でした。
社内向けツールに十分なUIと開発スピード
- 今回のアプリは社内利用が前提であるため、凝ったデザインや複雑な画面遷移は必要なく、Streamlitの最低限かつ十分なUIを短時間で構築できる点が良いと感じました。
データ基盤との親和性の高さ
アプリ概要
以上の前提を踏まえて、今回Streamlitで構築するアプリで解決したい課題とそれに伴う主な機能は以下です。
解決したい課題
現在のBigQueryの権限付与プロセスにはいくつかの課題があり、本アプリを用いてそれらの課題を解決したいと考えています。
1: 不正確な依頼情報の削減
現行のオペレーションでは依頼者がSlackワークフローにて入力したフリーテキストをもとに、管理者が目視確認して権限付与を行なっているフローのため、以下のような不正確な入力情報が頻発します。
その結果、依頼の多くで再確認が必要となり、必要以上に工数がかかっています。
不必要な工数を削減するためには、依頼を受けた時点での誤入力に対するバリデーション設定が必要です。
2: データ閲覧権限の付与対象の明確化
現行のオペレーションでは「誰にどのデータ閲覧権限を付与して良いか」が明確に決まっておらず、依頼を受ければほぼ全員に対して権限を付与している状態です。
しかし、ガバナンスの観点で、ユーザに必要最低限の権限を付与する体制を構築する必要があります。
主な機能
以上の課題を解決するためのツールとして、権限付与アプリには以下の機能を持たせることにしました。
- Slackワークフローからの権限付与依頼の受付
- 依頼内容の誤入力に対するバリデーション設定(課題1の解決)
- 管理者による承認
- ユーザへの適切な権限を自動付与(課題2の解決)
- 権限の一覧表示
要件定義
アプリで解決したい課題が明確になったので、ここからさらに細かい機能要件とデータ閲覧権限の付与対象を決めていきました。
機能要件
まずは機能要件を定義するためにアクティビティ図を作成しました。

前述した課題を解決するための機能は、このアクティビティ図にはそれぞれ以下の箇所で盛り込みました。
- 依頼内容の誤入力に対するバリデーション設定
- Slackワークフローからの申請を受け取ったタイミングで、誤入力に対するバリデーションを設定しました
- これにより管理者は正しく入力された依頼のみを確認できるようになります
- ユーザへの適切な権限を自動付与
- すべての権限付与は自動で行われるので、事前に定義した権限付与範囲の定義に基づいて適切に付与されます
また、アクティビティ図を作成する上で、議論に上がったのは以下の観点です。
ユーザ目線でどのようなアプリにするのが使いやすいか
- もともと権限付与依頼はアプリ上でフォームに入力してもらう予定でしたが、「ユーザー目線だと申請時にアプリにログインするのは面倒くさい」という意見があがりました
- この意見を尊重し、現場のユーザーが慣れているSlackワークフローでの依頼運用は変えずに、管理者だけがアプリ側で承認作業を行うことにしました
- 結果として、Streamlitアプリは「管理者が承認時に使用するオペレーションツール」という役割に特化することになりました
アクティビティは何をもって完了とするか
- 「アクティビティは何をもって完了とするか」については、単に権限を付与するだけでなく、その結果を依頼者に伝達し、データベースに記録するところまでを完了と定義しました
データ閲覧権限の付与対象の再定義
次に、どの権限を誰に付与してよいかを再定義しました。
今までは職種ごとに閲覧権限を付与するデータセットを分けていましたが、今後は部門×契約形態ごとに分けることにしました。
| 部門 | 契約形態 |
|---|---|
| 事業部* | 正社員 |
| 事業部 | 業務委託 |
| マーケティング部 | 正社員 |
| マーケティング部 | 業務委託 |
| システム本部 | 正社員 |
| システム本部 | 業務委託 |
※事業部:各種サービスの運営を担う部門。主に営業職および企画職が所属する。
職種ではなく部門ごとで分けることにした理由は、同じ職種でも部門を跨いで社内異動をすることになった際には異動前の部署で保有していた権限を剥奪したほうがよいと判断したためです。
また、契約形態ごとに分けることにした理由は、業務委託が閲覧できる社内のデータを最低限に制限するためです。
設計
ユーザービリティを最優先した新しいフローに基づき、具体的なシステム設計に移ります。
UI設計
まずはイメージを膨らませるために、アプリのUI(ラフ図)を書き起こしました。
今回は、①ログイン時の認証画面と、②管理者が承認するための画面と、③ユーザ別の権限検索をするための画面を設置しました。


アーキテクチャ設計
次に、アーキテクチャ設計を行なっていきます。
Streamlitの高速開発力と、GCPの堅牢な実行環境を組み合わせたサーバーレス構成を採用しました。
システム構成は以下の通りです。
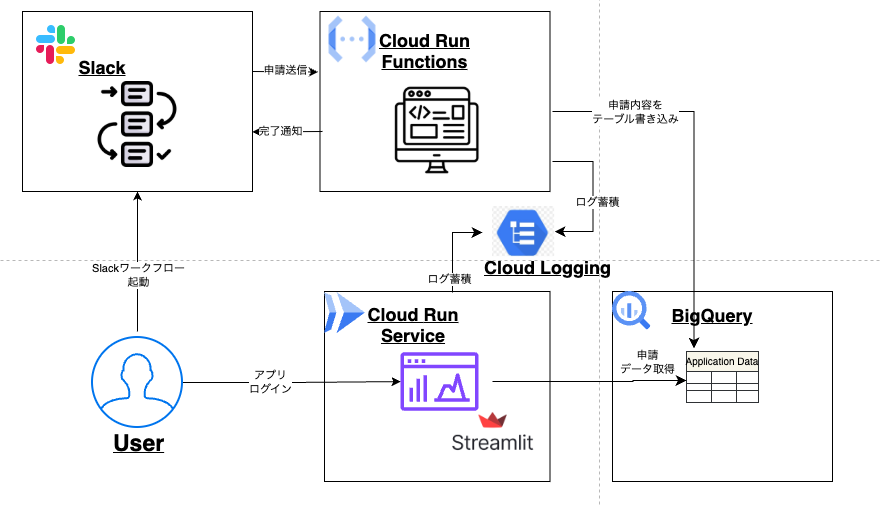
今回のシステム構成では、権限付与アプリの主要な機能はすべてStreamlitに集約しています。具体的には、Streamlitが管理者向けの承認・権限付与機能および権限一覧表示機能を担っています。
一方、Cloud Run Functionsは、ユーザーが利用するSlackワークフローからの申請を受け取り、その内容をBigQueryの申請履歴テーブルに書き込む役割のみを担っています。
各システムの技術選定理由は以下です。
| 技術 | 選定理由 |
|---|---|
| Streamlit | Pythonのみで実装可能、開発速度が速い |
| Cloud Run Service | サーバーレス、オートスケール対応 |
| Cloud Run Functions | Slackとの連携に最適 |
| BigQuery | 依頼履歴・権限情報の保存先として最適 |
おわりに
本記事では、StreamlitでBigQuery権限管理アプリを構築する際の要件定義と設計をご紹介しました。
初めてアプリ開発における要件定義と設計を実際にやってみて、ユーザーの利便性の観点でものづくりすることの重要性を学ぶことができました。また、Streamlitを軸にアーキテクチャ設計をすることで、自身のPythonスキルだけで実現できる道筋が見えたことは大きな収穫です。
引き続き、ガバナンス強化と運用効率化を両立させることを目標に、今後は実装に取り組んでいきます。