はじめに:AI開発特有の「評価の難しさ」とボトルネック
こんにちは。レバレジーズでエンジニアをしている安藤です。 最近は主に、LLMを組み込んだプロダクトの品質管理(QAや自動評価基盤の構築)に注力しています。
LLMを組み込んだシステムの品質管理は、従来のWebアプリケーション開発とは異なる、非常に厄介な課題を抱えています。 最大の壁となるのは、「LLMの非決定性」と「自然言語の多義性」です。
従来のシステムであれば、「Aという入力には必ずBが返る」という決定論的なテストコードを書くことができました。 しかしLLMの場合、同じプロンプトでも毎回出力が揺らぐ「非決定性」を持っています。
さらに、ユーザーの入力する自然言語は多義的で無数のバリエーションがあるため、 事前にすべてのテストケースを網羅し「100%の正解」を定義することは実質不可能です。 現在私が関わっているAIプロダクトの開発でも、この壁にぶつかりました。(まだまだ試行錯誤中です)
答えがない中ですが、まず方向性として、「誰でも、いつでも、できるだけ簡単に、品質評価できる状態」を目指すことにしました。 その上で重要だった考え方が、AIの回答が本当に「顧客に約束する価値」を満たしているか (適切な会話のキャッチボールができているか、不適切な発言をしていないか)をより的確に判断できるのは、エンジニアよりもビジネス側のメンバー(PdMやドメインエキスパート)だということです。
特に、AIプロダクトであればビジネス側のメンバーの関わりが非AIプロダクトよりも多くなります。 LLMへのプロンプトはドメイン知識の塊であり、ビジネス側のメンバーがプロンプトを更新することも日常茶飯事だからです。
しかし、更新のたびにエンジニアがローカルで評価スクリプトを回し、結果を非エンジニアに渡すというフローでは、「エンジニアへの依存(評価のボトルネック)」が発生してしまいます。
だからといって、社内検証用の専用Webアプリケーションをイチから開発・保守する余裕はありません。
そこで私たちが目をつけたのが、
「GitHub Actionsの手動実行(workflow_dispatch)を、非エンジニア向けのUIとして利用する」というアプローチでした。
なぜGitHub Actionsを「非エンジニア向けUI」にしたのか?
「GitHub ActionsはエンジニアがCI/CDで使うもの」というイメージが強いですが、workflow_dispatch の inputs を活用すると、以下のような項目を選択できる立派な入力フォームが出来上がります。
- 評価モデルの選択(Gemini 2.5 Pro / Flash など)
- プロンプトタグの選択
- 実行回数
【エンジニアのメリット】
* React等を使ったフロントエンド画面の実装が不要
* 認証や権限管理はGitHubの仕組みに丸投げできる
* バックエンドのインフラ構築も不要
【ツール利用者(非エンジニア)のメリット】
* 「Run workflow」ボタンを押し、プルダウンを選んで実行するだけ(学習コスト低)
* 自分の好きなタイミングで、数十〜数百件の仮説検証をオンデマンドで回せる
エンジニアリングの経験がない方にGitHubを触ってもらうのは少しハードルがあるかと思いましたが、 「ここだけポチポチすれば動くよ」とドキュメント化するだけで、十分実用的な社内ツールとして機能させることができました。
アーキテクチャと連携フロー(生成と評価の分離)
重たいAIのテストを安定して回すため、 アーキテクチャは「会話ログの生成」と「評価」のリポジトリ(責務)を分離しています。
以下がその全体のシーケンス図です。
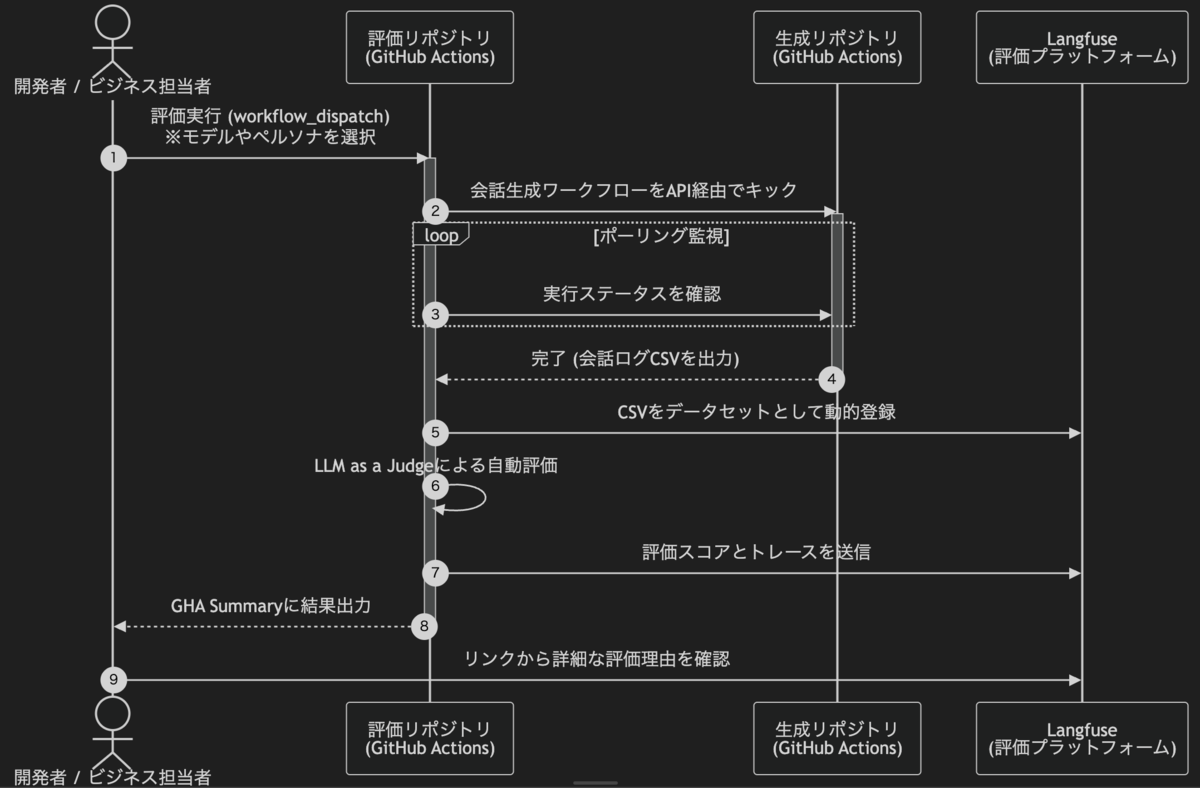
ビジネス側のメンバーが評価を実行すると、評価側のワークフローがAPI経由で生成用ワークフローをキックし、ポーリングして完了を待つという疎結合なアーキテクチャをとっています。
これにより、各コンポーネントの独立性を保ちつつ、ボタン一つで一連のフローが完結する仕組みを実現しました。
Langfuse連携とJob Summaryによる「結果の可視化」
ここまでで実行基盤は整いました。ただ非エンジニアにとって「実行したあと、結果をどこで見ればいいの?」は重要な問題です。
そこで、実行の最後に $GITHUB_STEP_SUMMARY を活用し、GitHubの実行結果画面にMarkdownでサマリーが表示されるようにしました。
さらに、生成されたデータはPythonスクリプトで動的にLangfuseのデータセットに同期されます。これにより、専用UIを作らなくても、Langfuseの優れたUIに飛ばすことでリッチな分析体験を提供できます。
このように、サマリと詳細確認のUIを分離することで、「サッと理解し、問題があれば精査する」がしやすい仕組みにしました。
おわりに:AI評価の「民主化」に向けた第一歩
この評価基盤はまだ開発して間もなく、実運用はこれから本格化していくフェーズです。
現時点で「評価プロセスが完全に自動化・民主化された」と言い切るにはまだ早く、今後の継続的なモニタリングと改善が必要です。
しかし、「専用の開発工数をかけず、既存ツール(GitHub Actions × Langfuse)の組み合わせだけでオンデマンドな評価環境を最速で組み上げた」ことは、リソースの限られた開発現場において非常に意義のある一歩だったと感じています。
今後はこの基盤へのフィードバックをもとに、さらに改善改良を加え、チーム全体でAIの品質を継続的に引き上げていく文化(AI評価の民主化)を作っていきたいと考えています。